Large-scale systems architecture: lessons from 'Designing data-intensive applications'
Reliability, scalability and maintainability as pillars of every modern system. Comparative use cases, technology tables and FAQs to understand how to design systems that survive growth.



1 / 15
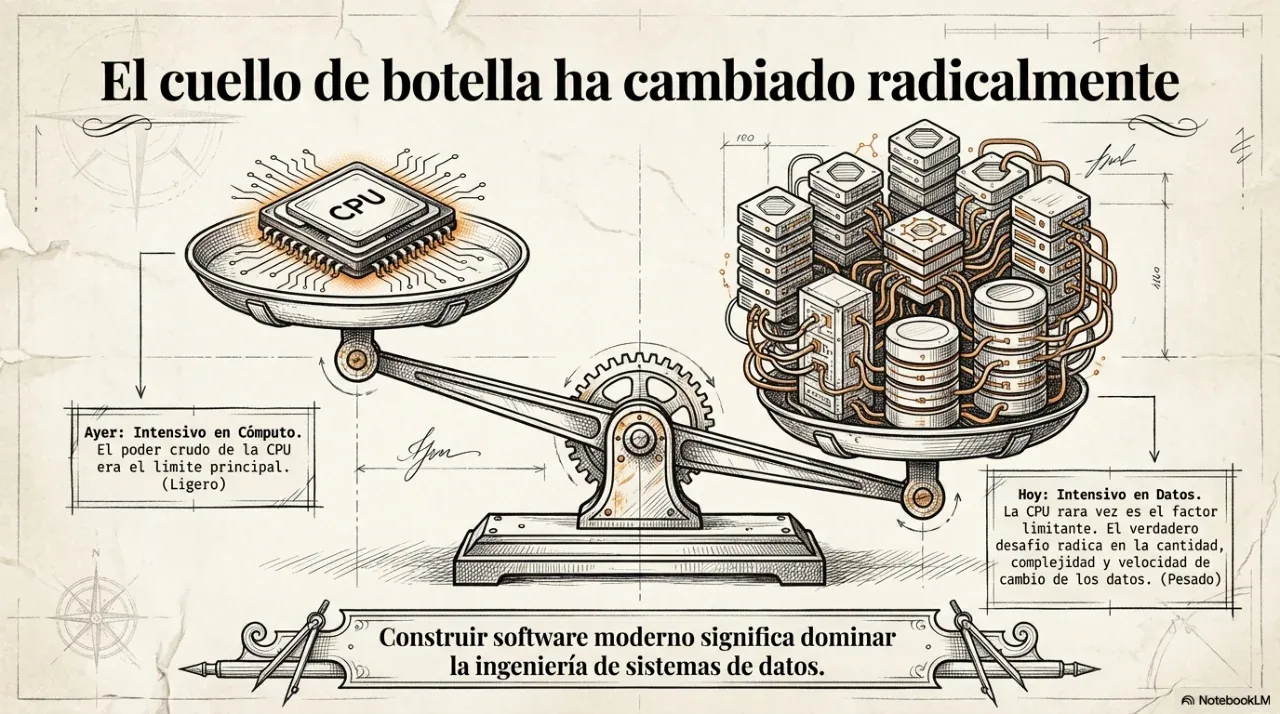
How many times have you heard that a system “went down because of traffic”? Behind that sentence there is usually an architecture decision that was made poorly, or not made at all. This article takes the industry reference Designing Data-Intensive Applications by Martin Kleppmann and turns it into concrete decisions that any growing business needs to understand.
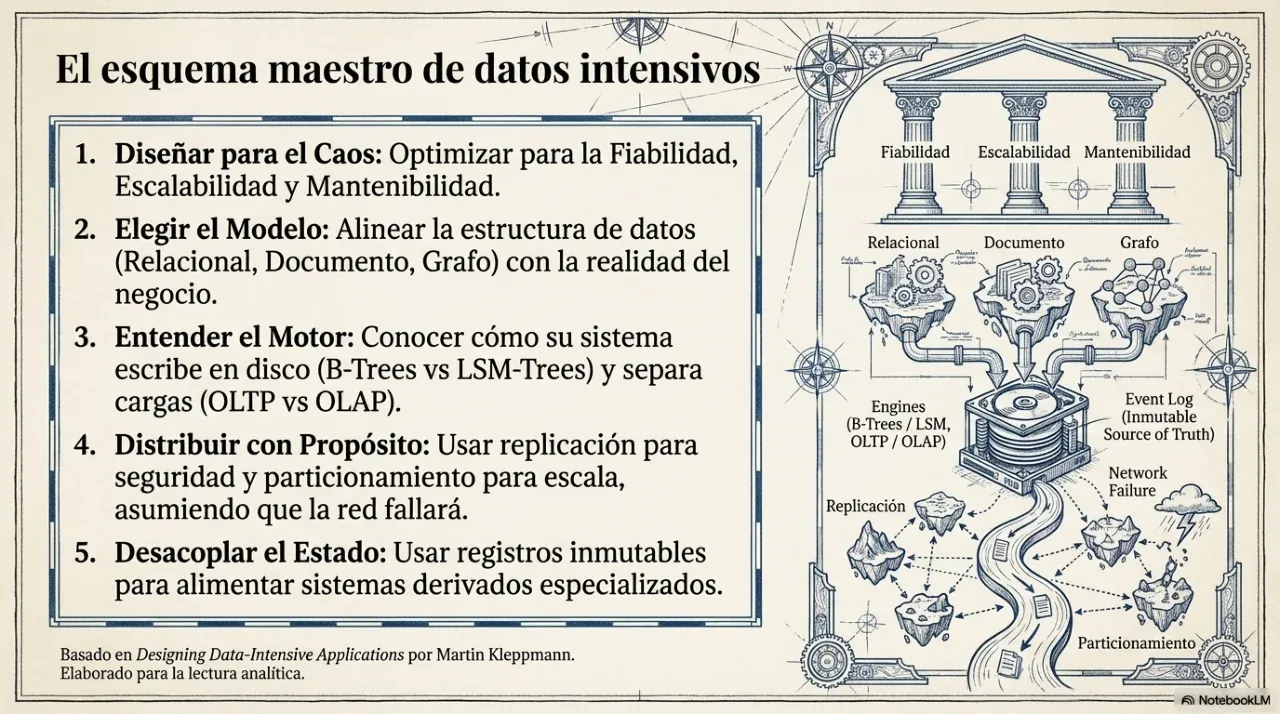
1. The three pillars of every data-intensive system
Every system that handles data at scale should be evaluated through three business questions.
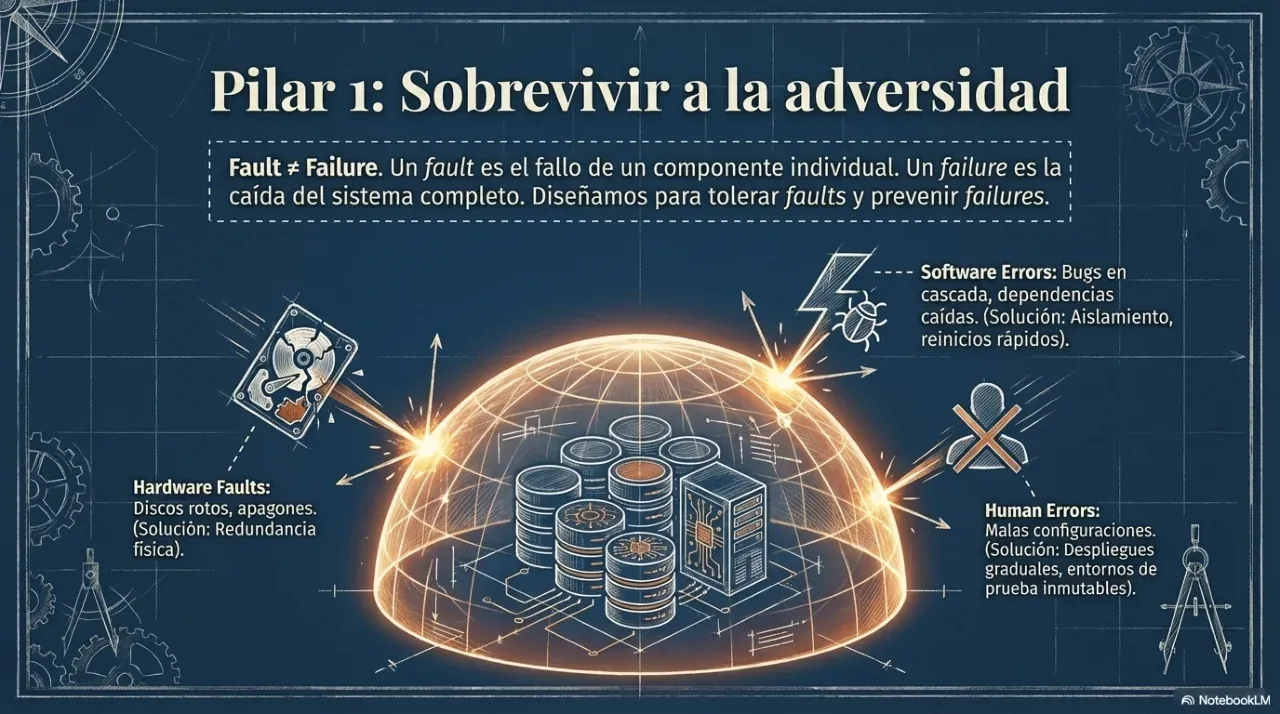
Reliability. Does the system keep working when a server fails, the network is interrupted, or a user does something unexpected? A reliable system fails in a controlled way, not catastrophically.
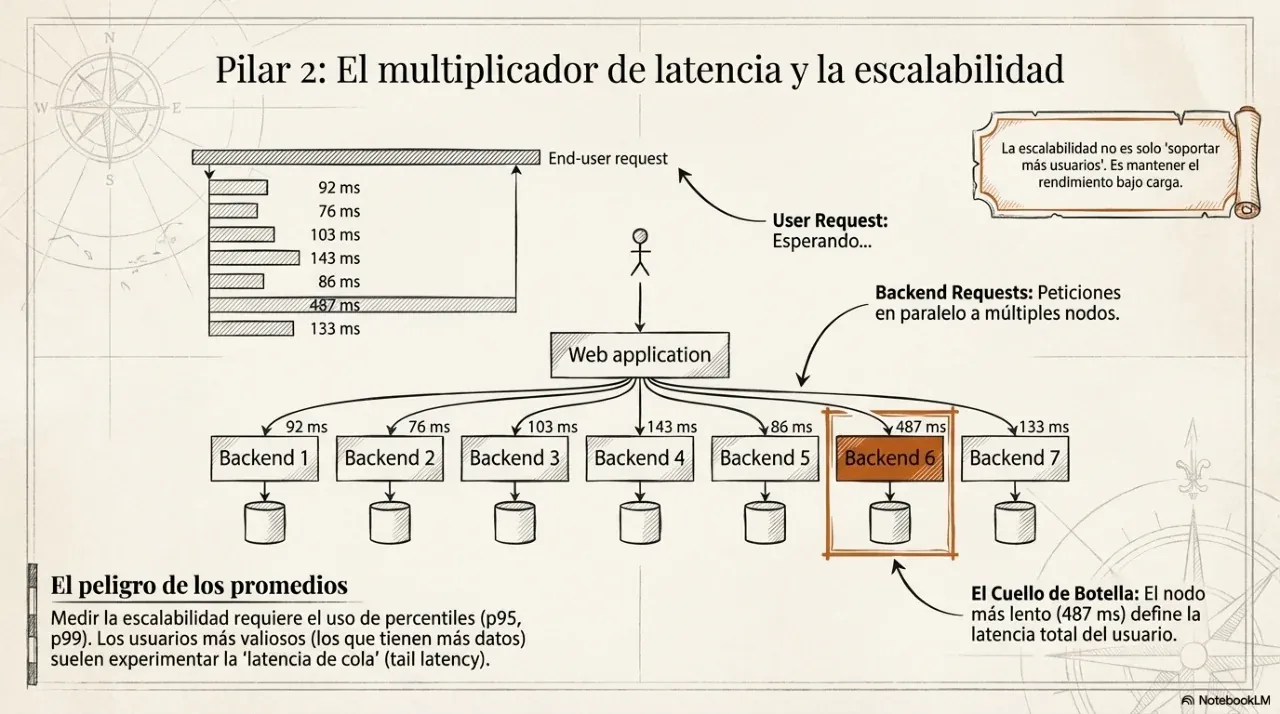
Scalability. What happens when volume grows by 10x? “We’ll see when it happens” is not an architecture. Architecture defines in advance how far the system can grow before it must be rewritten.
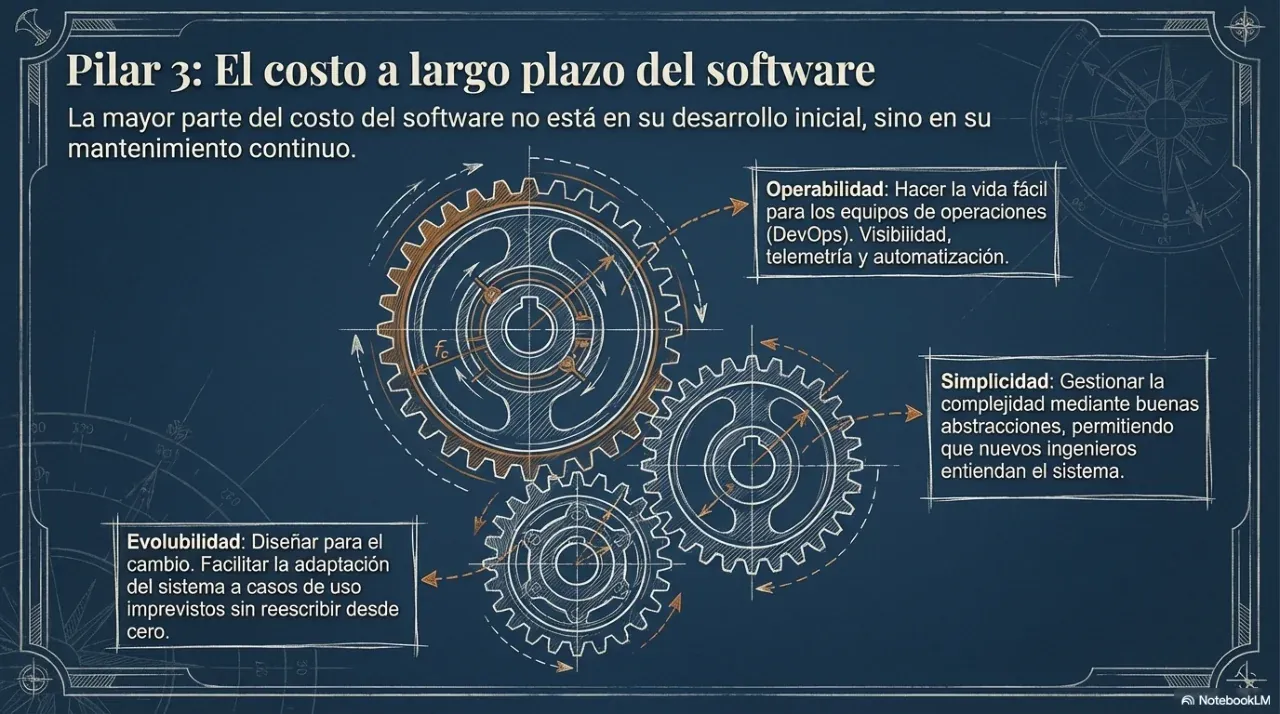
Maintainability. Can another person, or you in six months, work on the system without breaking everything? Maintainable systems keep technical debt under control, use coherent documentation, and separate responsibilities clearly.
These dimensions are not independent. Optimizing only one of them almost always degrades the other two.
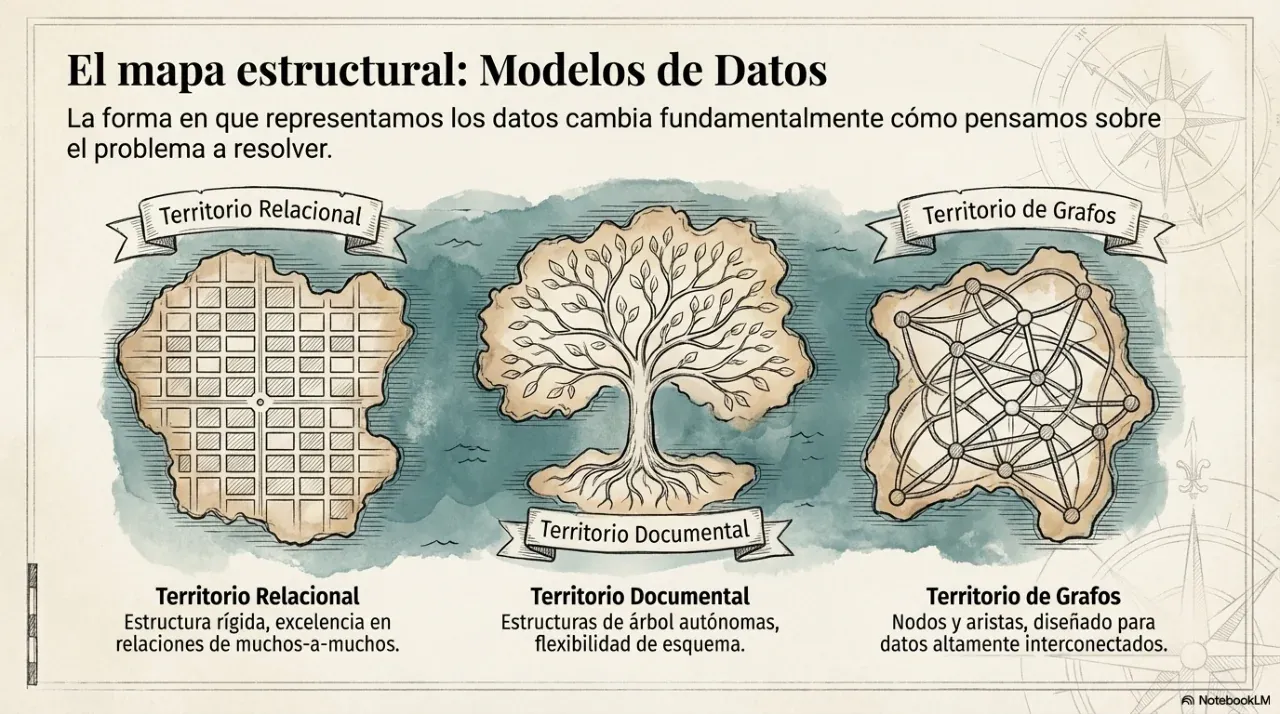
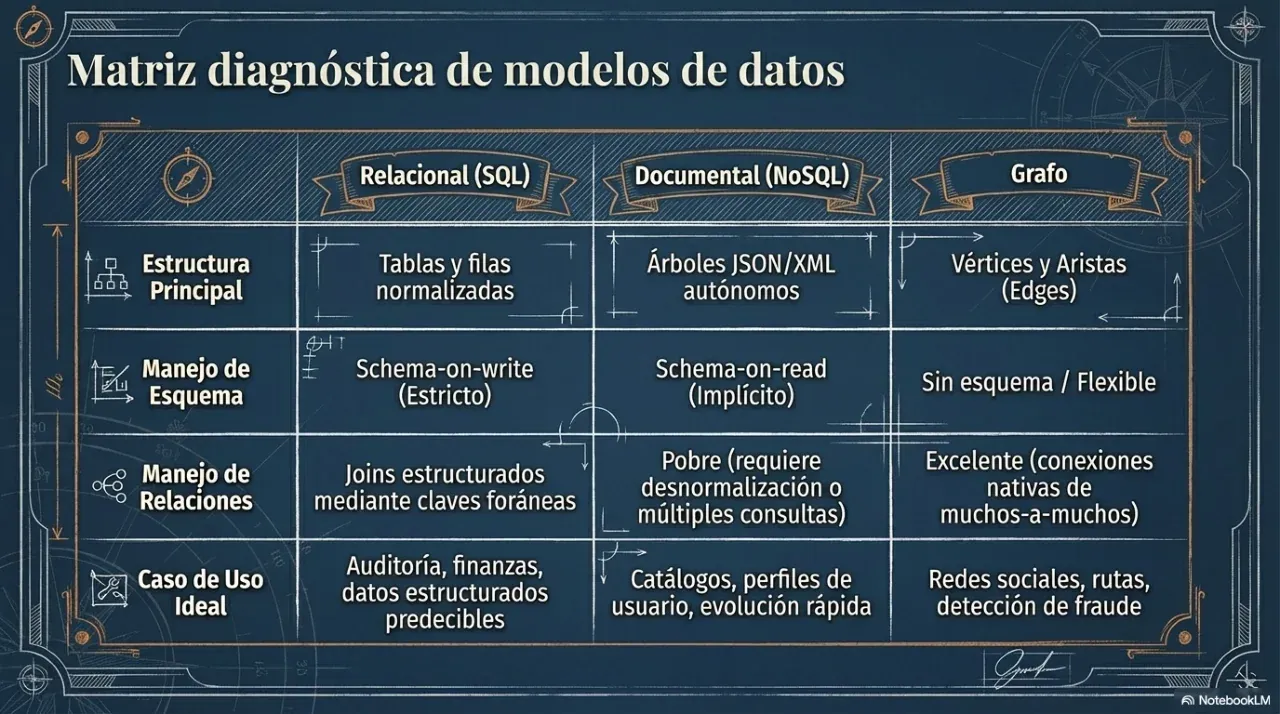
2. Data models: when to use SQL and when not to
The most frequent and most expensive decision in a project is choosing the database engine. The criterion is not what is fashionable, but which data model best represents the business problem.
SQL relational databases
Use SQL when data has complex relationships, when transactional guarantees matter, and when consistency is non-negotiable. Money flows, inventory, billing, and booking systems are classic examples.
Document-oriented NoSQL
Use document databases when the read unit is a self-contained document and structure varies between records. User profiles and product catalogs with category-specific attributes are common examples.
Columnar NoSQL
Use columnar storage for analytics over large volumes of historical data where queries read a few columns across many rows. Metrics dashboards over millions of events fit this model.
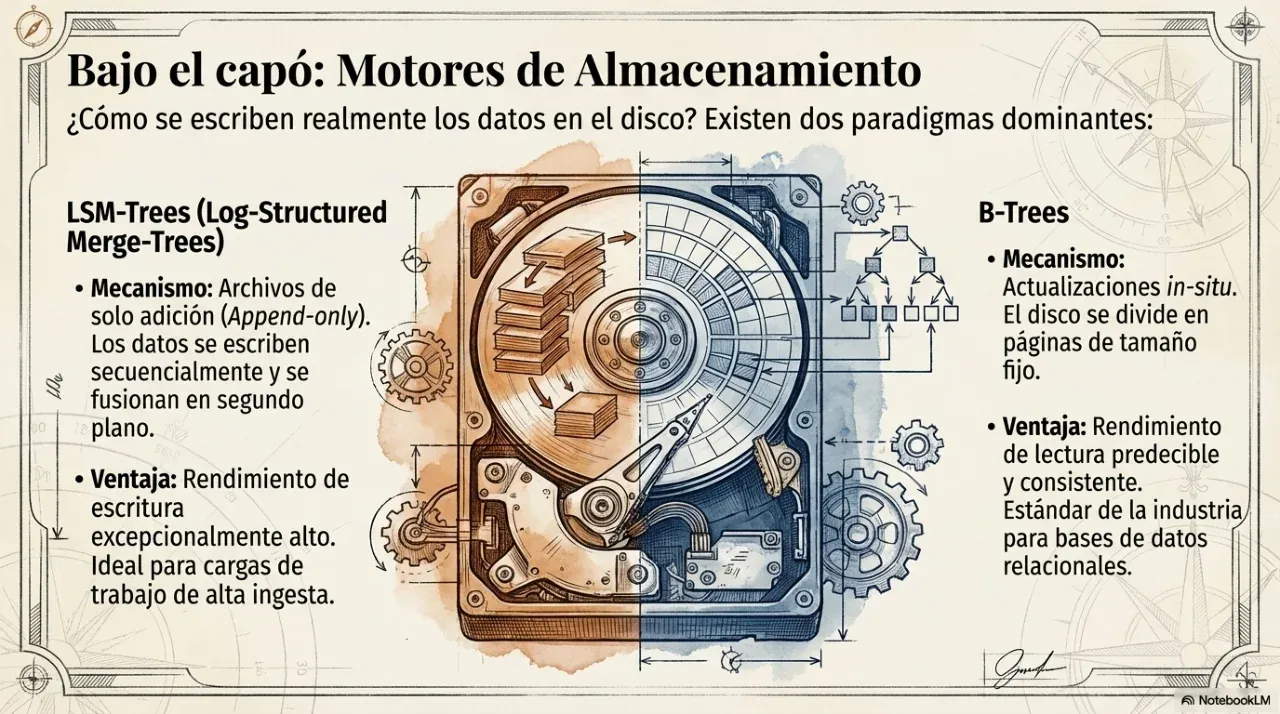
3. Replication: consistency vs availability
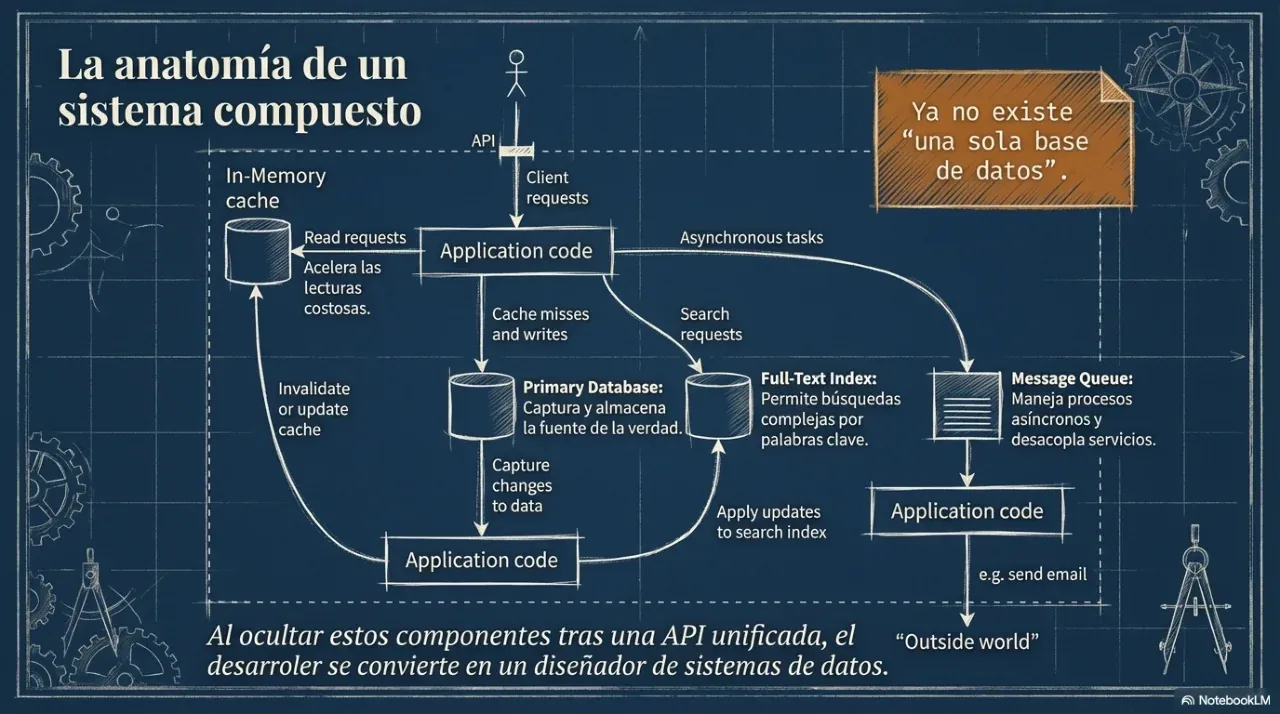
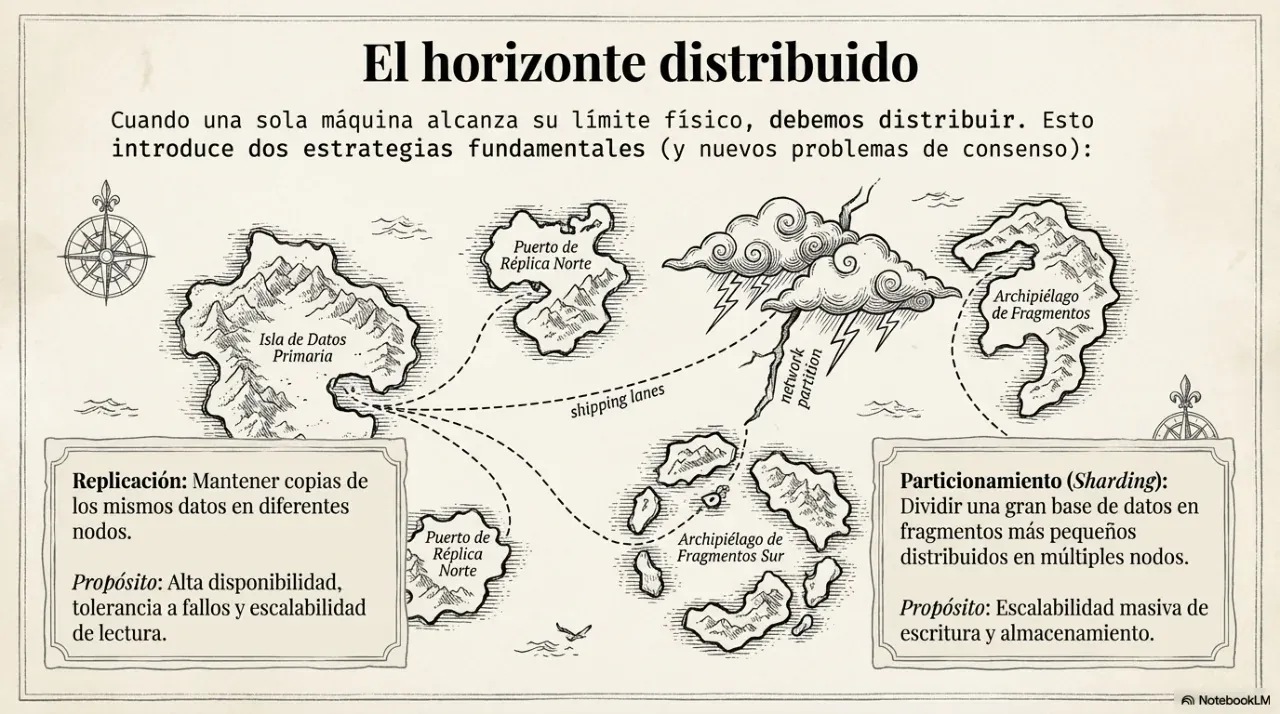
When a system grows, data is replicated across multiple nodes to resist failures. The hard part is that nodes can become temporarily out of sync. That is where the most important distributed architecture decision appears.
Single-leader
All writes go through a central node that determines operation order. This gives strict consistency: after writing data, the next read reflects it. The cost is that the leader becomes a bottleneck and a single point of failure.
Use it for financial systems, critical inventory, and flows where inconsistency has direct economic consequences.
Leaderless
Any node can accept writes. Conflicts are resolved on read through version vectors or application logic. This favors high availability: the system can keep accepting writes even if a node is down.
Use it for carts, likes, counters, and flows where losing a write is worse than seeing temporarily inconsistent data.
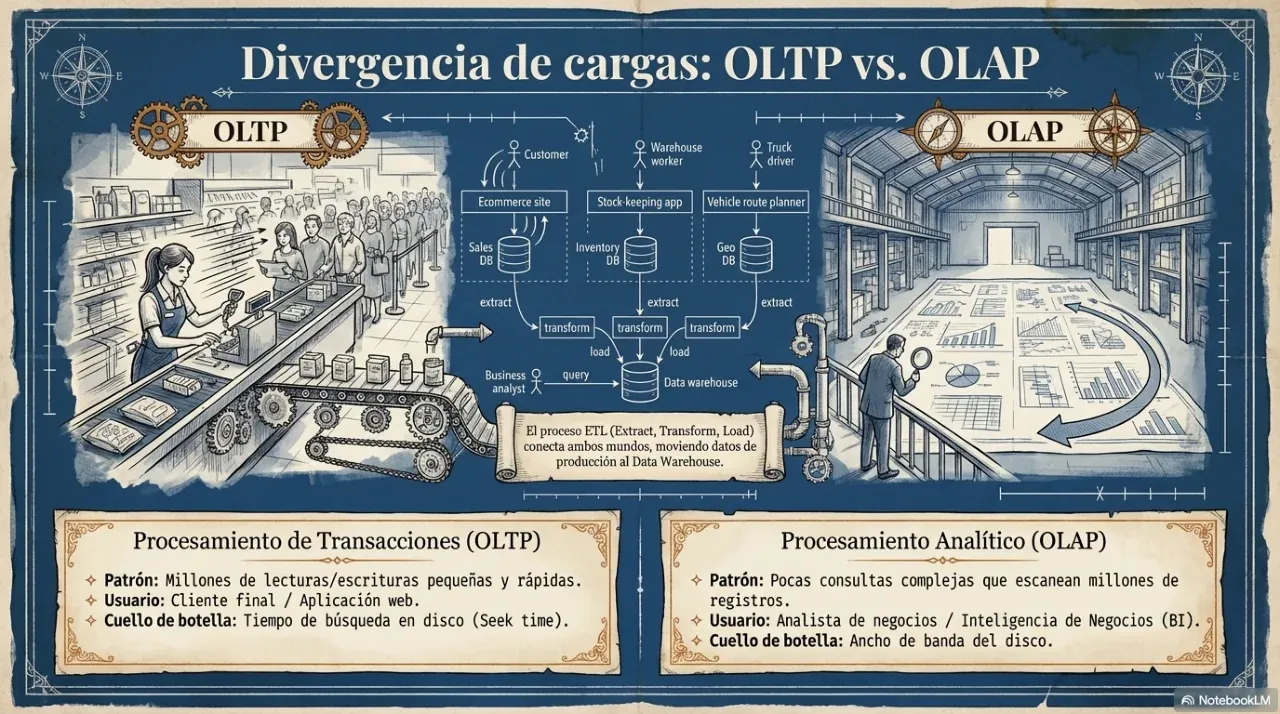
4. Batch vs stream processing
Once data is stored, it must be processed. The question is when: over accumulated data or over events in real time?
Batch processing runs over a fixed historical dataset. Latency is high, often minutes or hours, but throughput is excellent. It is ideal for reports, trend analysis, and tasks that do not require immediate response.
Stream processing runs as events happen. Latency is low, from milliseconds to seconds, but complexity is higher. It is ideal for fraud detection, real-time alerts, and continuous data pipelines.
5. Technology choices by use case
| Use case | Critical dimension | Recommended model | Reference technology | Why not the alternative |
|---|---|---|---|---|
| Payments and charges | ACID consistency | Relational SQL | PostgreSQL | NoSQL without transactions can duplicate charges |
| User profiles with variable fields | Schema flexibility | Documents | MongoDB | SQL requires migrations for each new field |
| Black Friday cart | High availability | Leaderless | Cassandra / DynamoDB | Single-leader rejects writes if the leader fails |
| Account balance dashboard | Strict read consistency | Single-leader | PostgreSQL with read replica | Leaderless can show stale balances |
| Monthly sales report | Historical throughput | Batch | Spark / dbt | Stream is unnecessarily complex |
| Credit-card fraud detection | Sub-second latency | Stream | Kafka + Flink | Batch detects fraud too late |
6. Frequently asked questions
What is CAP and why does it matter?
CAP says that when a network partition happens, a distributed system can guarantee either consistency or availability, but not both at the same time. A banking system chooses consistency: it prefers returning an error over showing an incorrect balance. A shopping cart chooses availability: it prefers saving the item and resolving conflicts later.
When does sharding make sense?
Sharding makes sense when data volume or query load exceeds what a single server can handle. The key risk is choosing a bad partition key. If all records for the same customer go to the same node, that node becomes a hot spot. A good partition key distributes load evenly.
What is eventual consistency?
It means that if writes stop, all nodes eventually converge to the same value. It is not permanent inconsistency; it is controlled synchronization delay. For a client, the explanation is simple: the change is safely saved, but some users may see the previous value for a few seconds while propagation completes.
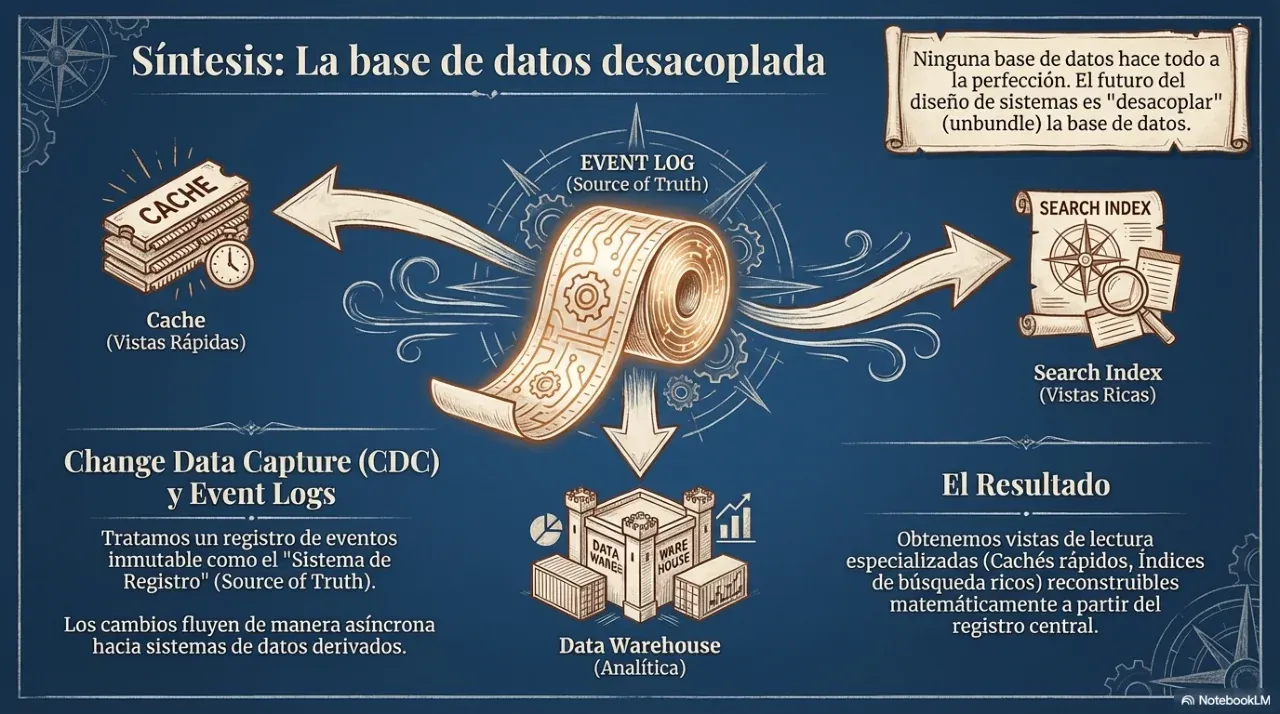
Is Kafka a database?
Not exactly, but it is not just a message queue either. Kafka is a distributed persistent event log. Messages are retained for a configurable period, so multiple consumers can read them independently, rewind, and rebuild derived views.
7. Next step
The first step is not choosing technologies. It is mapping which dimension is critical for your case: consistency, availability, or processing latency.
We can do that analysis together. Contact us through WhatsApp or email, and we can start with a free diagnosis.
Sources and references
- Designing Data-Intensive Applications — Martin Kleppmann (2017)