Arquitectura de sistemas a gran escala: lecciones de 'Designing data-intensive applications'
Confiabilidad, escalabilidad y mantenibilidad como pilares de todo sistema moderno. Casos de uso comparativos, tablas de tecnologías y preguntas frecuentes para entender cómo diseñar sistemas que sobreviven al crecimiento.



1 / 15
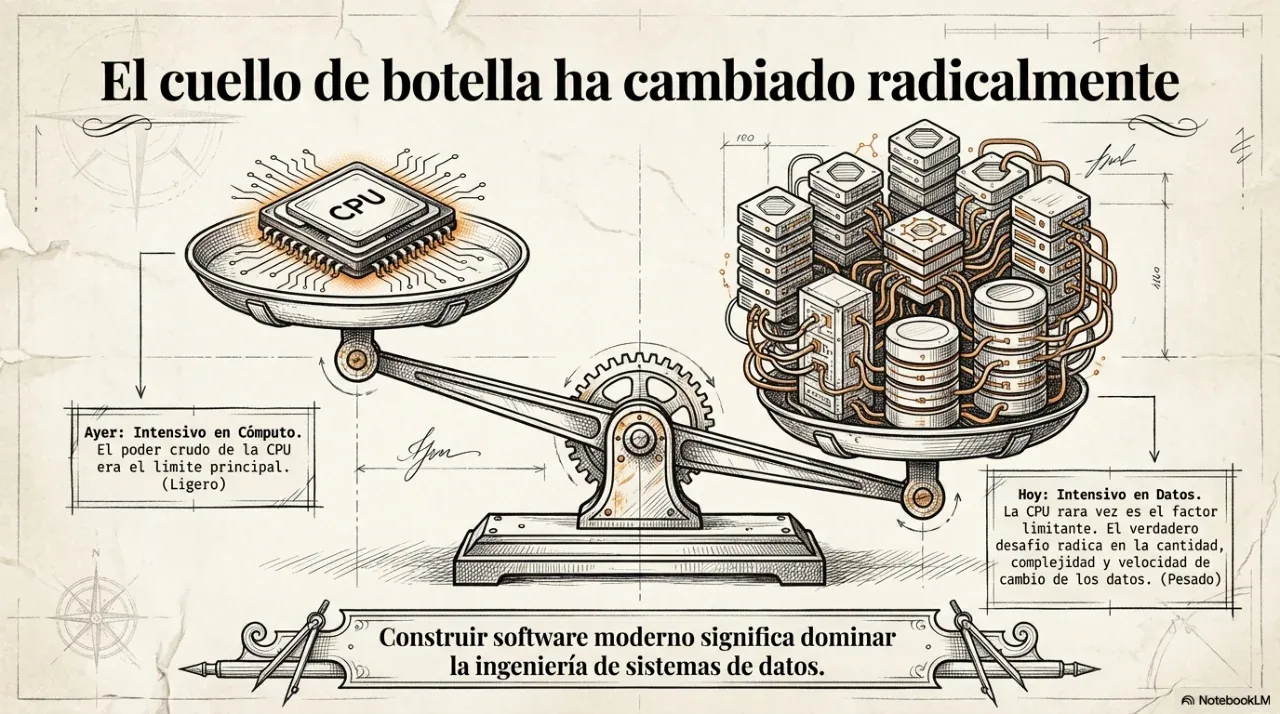
¿Cuántas veces escuchaste que un sistema “se cayó por el tráfico”? Detrás de esa frase hay una decisión de arquitectura que se tomó mal, o directamente no se tomó. Este artículo parte del libro de referencia de la industria —Designing data-intensive applications, de Martin Kleppmann— y lo traduce a decisiones concretas que cualquier negocio en crecimiento necesita entender.
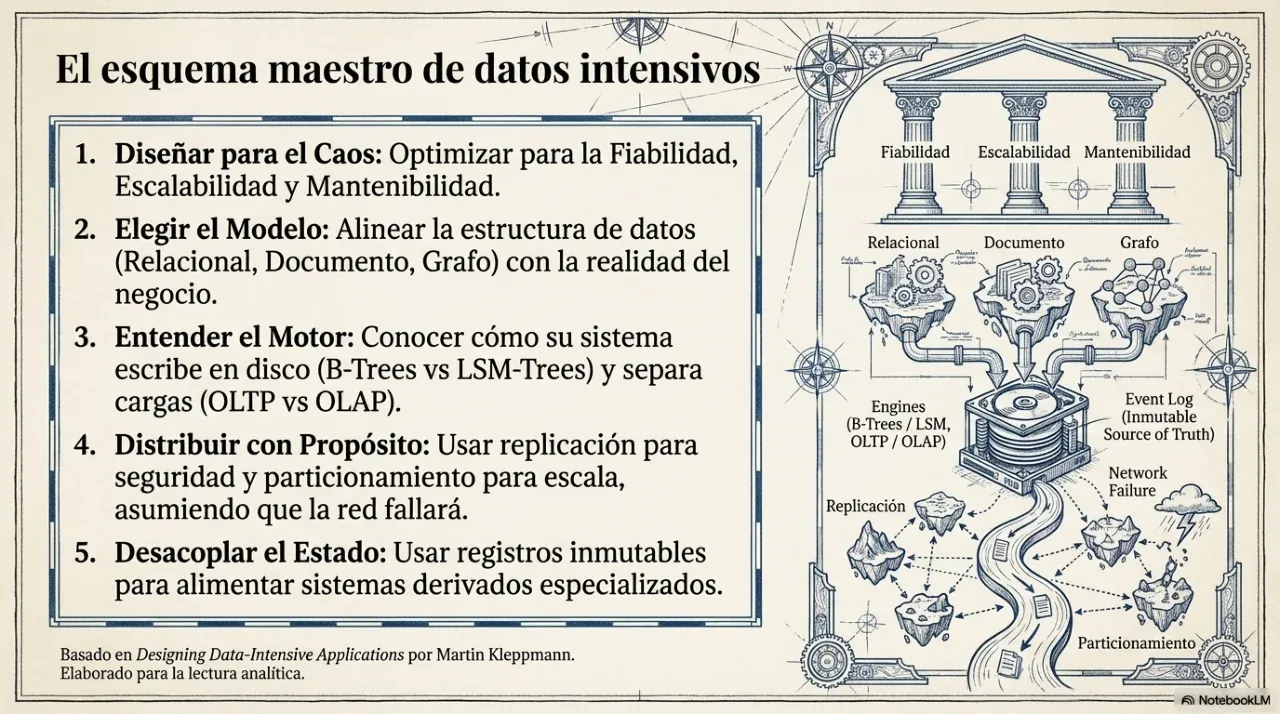
1. Los tres pilares de todo sistema intensivo en datos
Todo sistema que maneja datos a escala debe evaluarse bajo tres preguntas que no son técnicas sino de negocio:
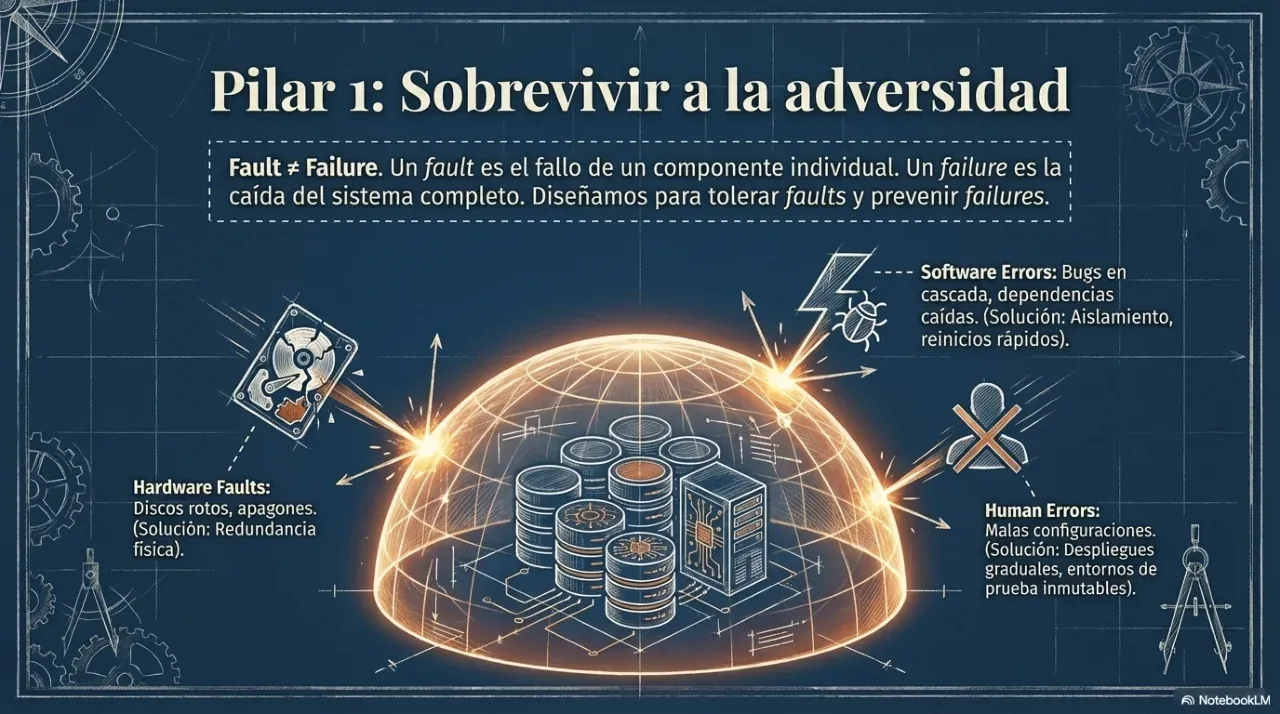
Confiabilidad. ¿El sistema sigue funcionando cuando falla un servidor, se corta la red o un usuario hace algo inesperado? Un sistema confiable falla de forma controlada, no de forma catastrófica.
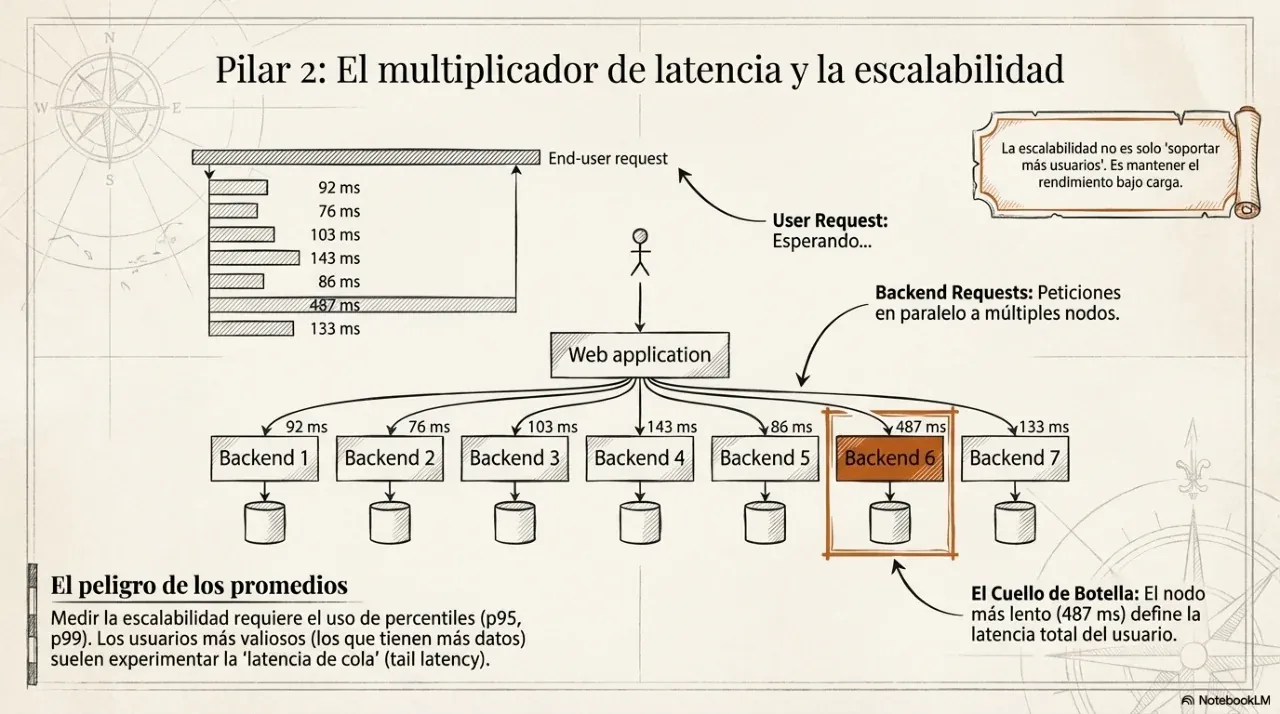
Escalabilidad. ¿Qué pasa cuando el volumen se multiplica por diez? La respuesta no puede ser “lo vemos cuando llegue ese momento”. La arquitectura define de antemano cuánto puede crecer el sistema sin reescribirse.
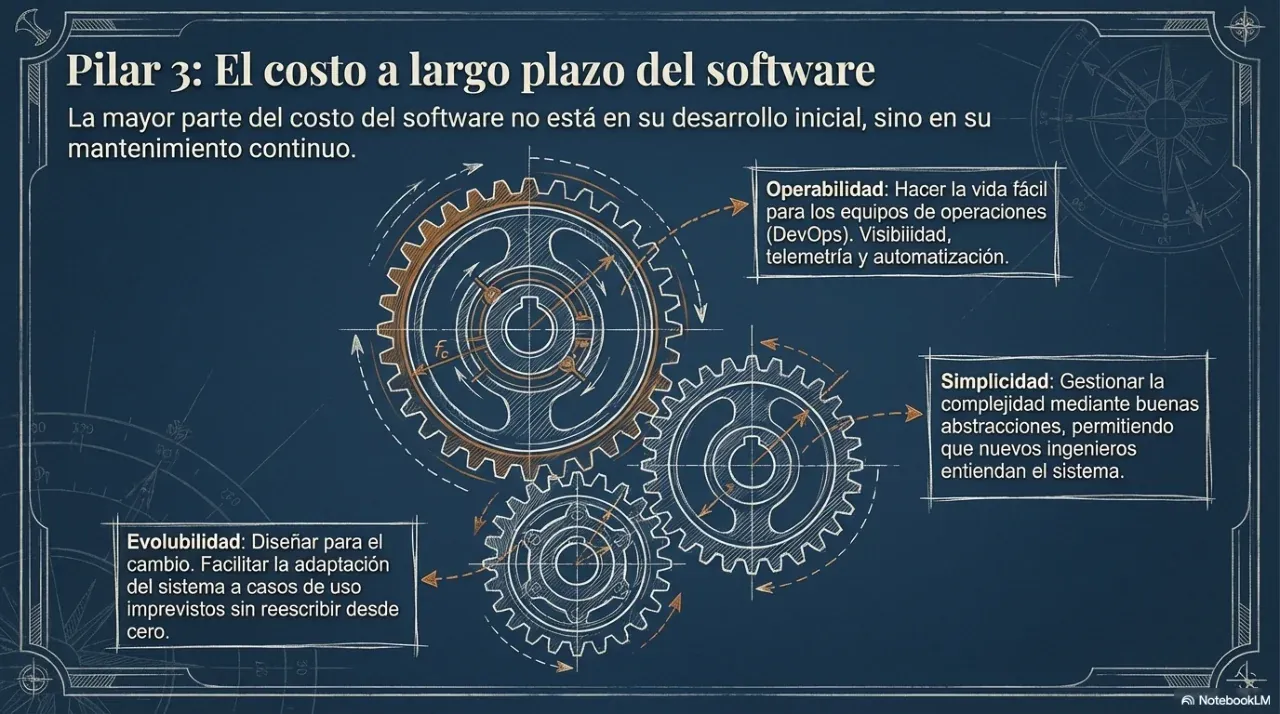
Mantenibilidad. ¿Puede otra persona —o vos mismo en seis meses— trabajar en el sistema sin romper todo? Un sistema mantenible tiene deuda técnica bajo control, documentación coherente y separación clara de responsabilidades.
Estas tres dimensiones son el marco que Kleppmann usa para evaluar cualquier decisión técnica. No son independientes: optimizar solo una de ellas casi siempre degrada las otras dos.
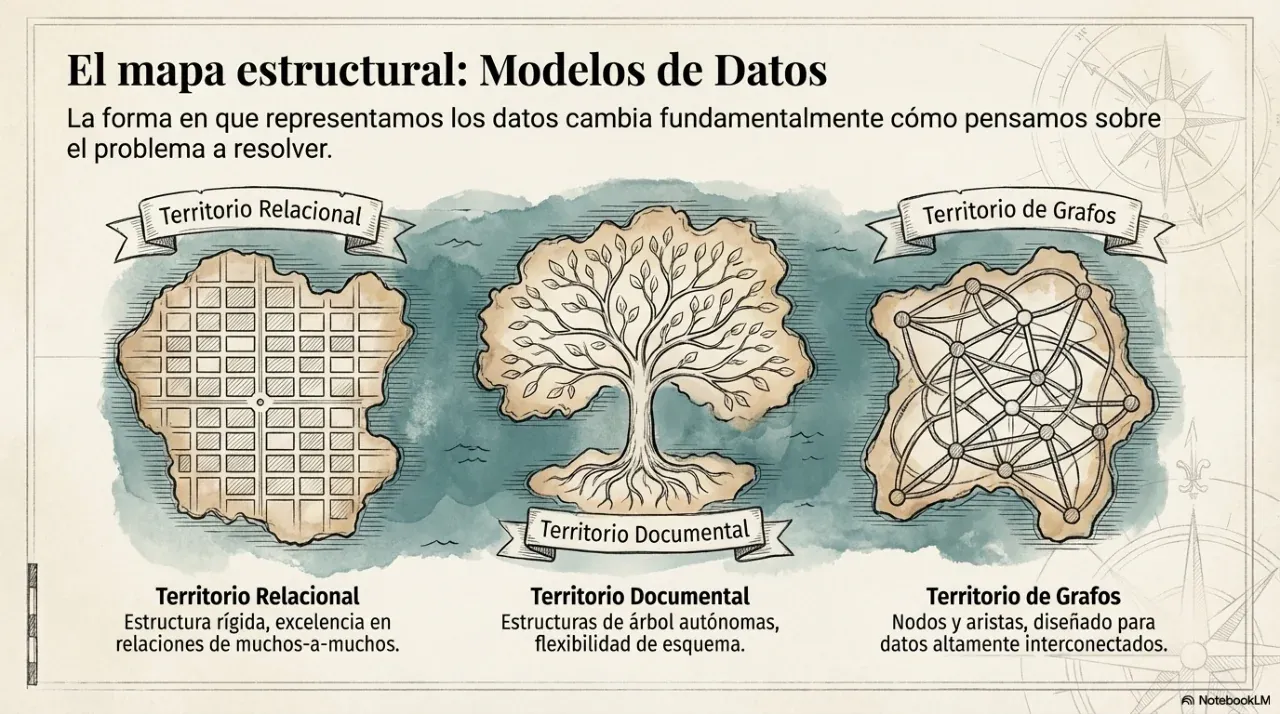
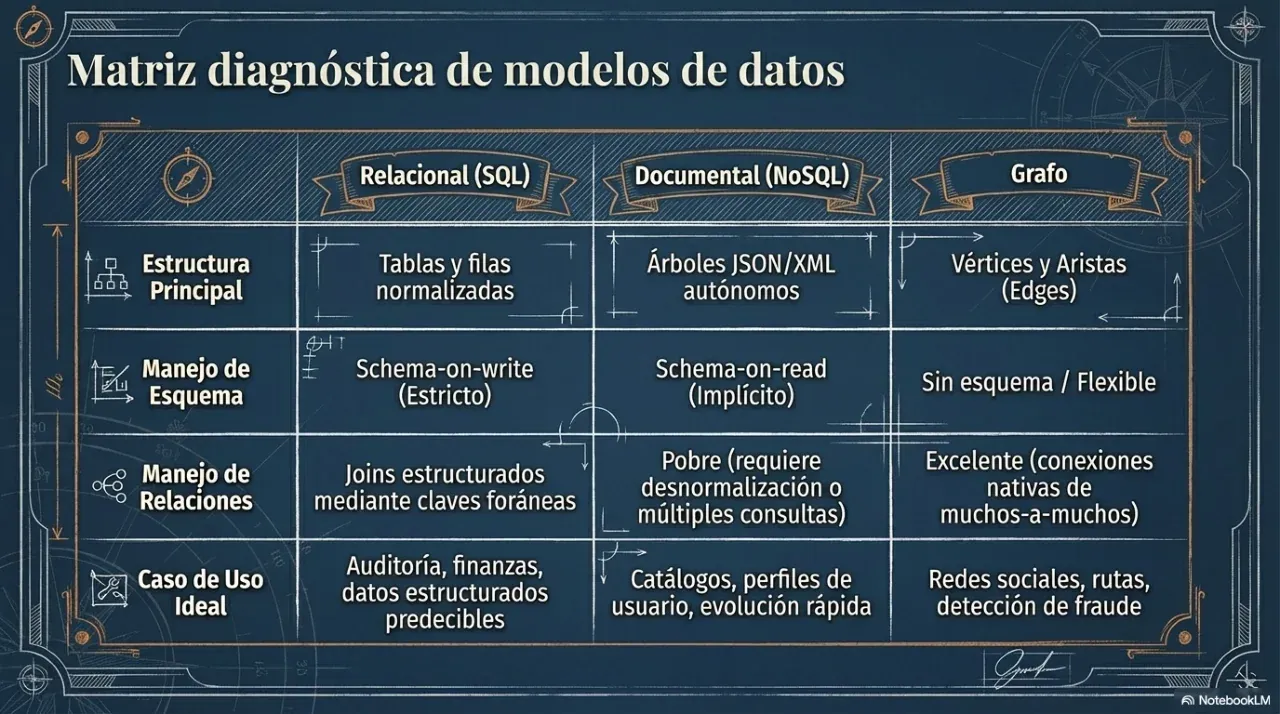
2. Modelos de datos: cuándo usar SQL y cuándo no
La decisión más frecuente y más mal tomada en cualquier proyecto es la elección del motor de base de datos. El criterio no es “qué está de moda” sino qué modelo de datos representa mejor el problema de negocio.
SQL (bases de datos relacionales)
Ideal cuando los datos tienen relaciones complejas entre entidades, se necesitan garantías transaccionales (ACID) y la consistencia es innegociable. El caso clásico es cualquier flujo de dinero: cobros, stock, facturación.
Ejemplos: PostgreSQL, MySQL.
NoSQL orientado a documentos
Ideal cuando la unidad de lectura es un documento autocontenido y la estructura del dato varía entre registros. El caso clásico es un perfil de usuario o un catálogo de productos con atributos distintos por categoría.
Ejemplos: MongoDB, Couchbase.
NoSQL columnar
Ideal para analítica sobre grandes volúmenes de datos históricos donde se leen pocas columnas de muchas filas. El caso clásico es un dashboard de métricas sobre millones de eventos.
Ejemplos: Apache Cassandra, ClickHouse.
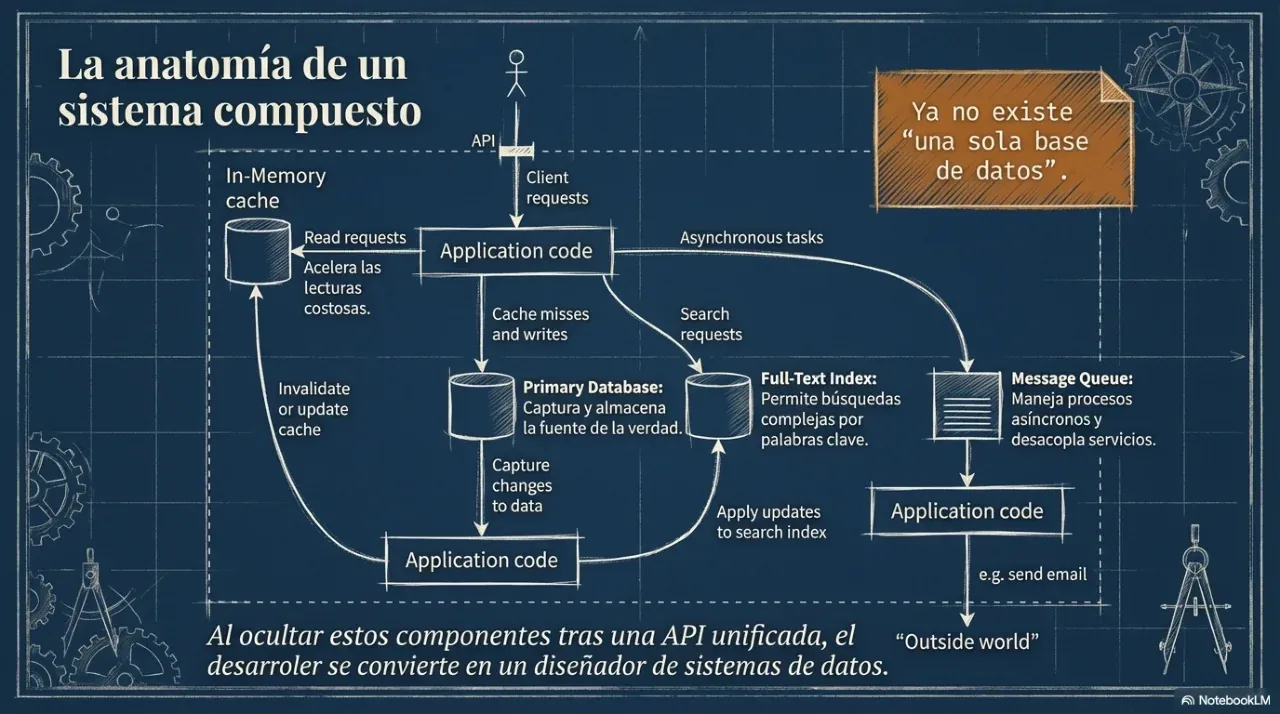
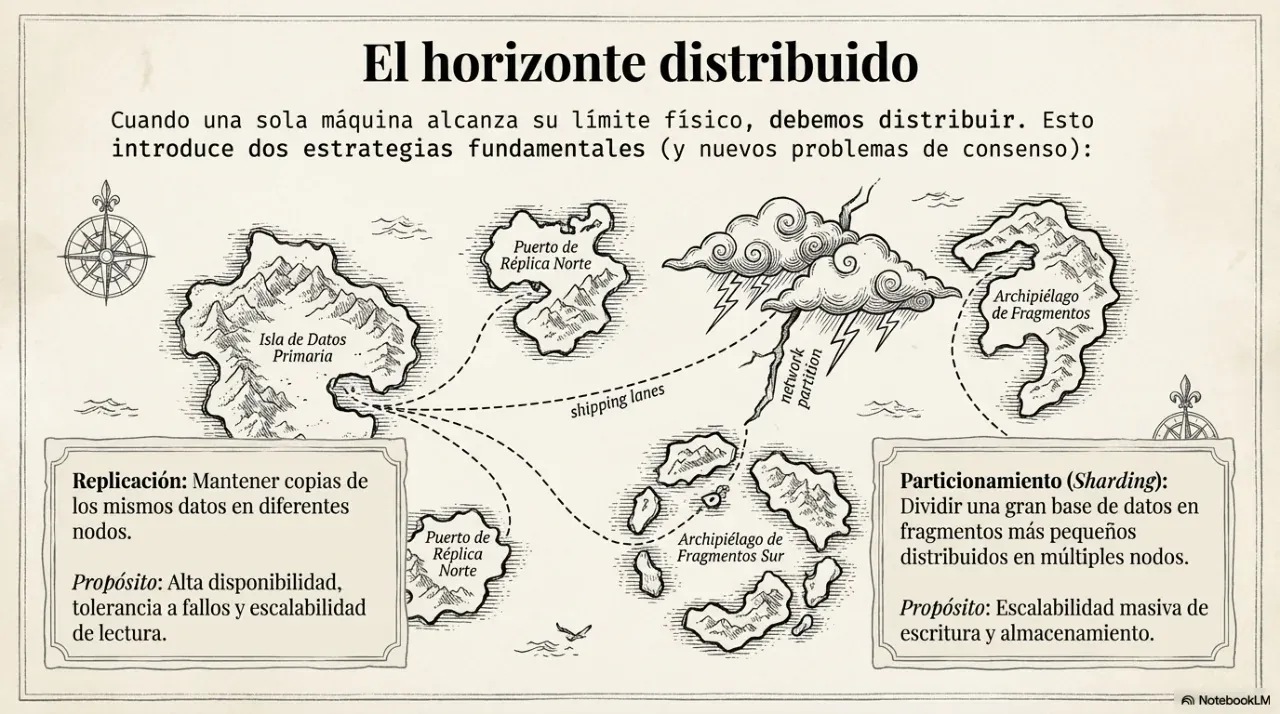
3. Replicación: consistencia vs. disponibilidad
Cuando un sistema crece, los datos se replican en múltiples nodos para resistir fallas. El problema es que los nodos pueden desincronizarse, y ahí aparece la decisión más importante de la arquitectura distribuida.
Single-leader (un solo líder)
Todas las escrituras pasan por un nodo central que determina el orden de las operaciones. Garantiza consistencia estricta: si escribís un dato, la próxima lectura lo refleja. El costo es que el líder es un cuello de botella y un punto único de falla.
Cuándo usarlo: sistemas financieros, inventario crítico, cualquier flujo donde una inconsistencia tenga consecuencias económicas directas.
Leaderless (sin líder, tipo Dynamo)
Cualquier nodo acepta escrituras. Los conflictos se resuelven en la lectura mediante vectores de versión o lógica de la aplicación. Garantiza alta disponibilidad: el sistema nunca rechaza una escritura aunque un nodo esté caído.
Cuándo usarlo: carritos de compra, contadores de likes, cualquier flujo donde perder una escritura sea peor que tener un dato temporalmente inconsistente.
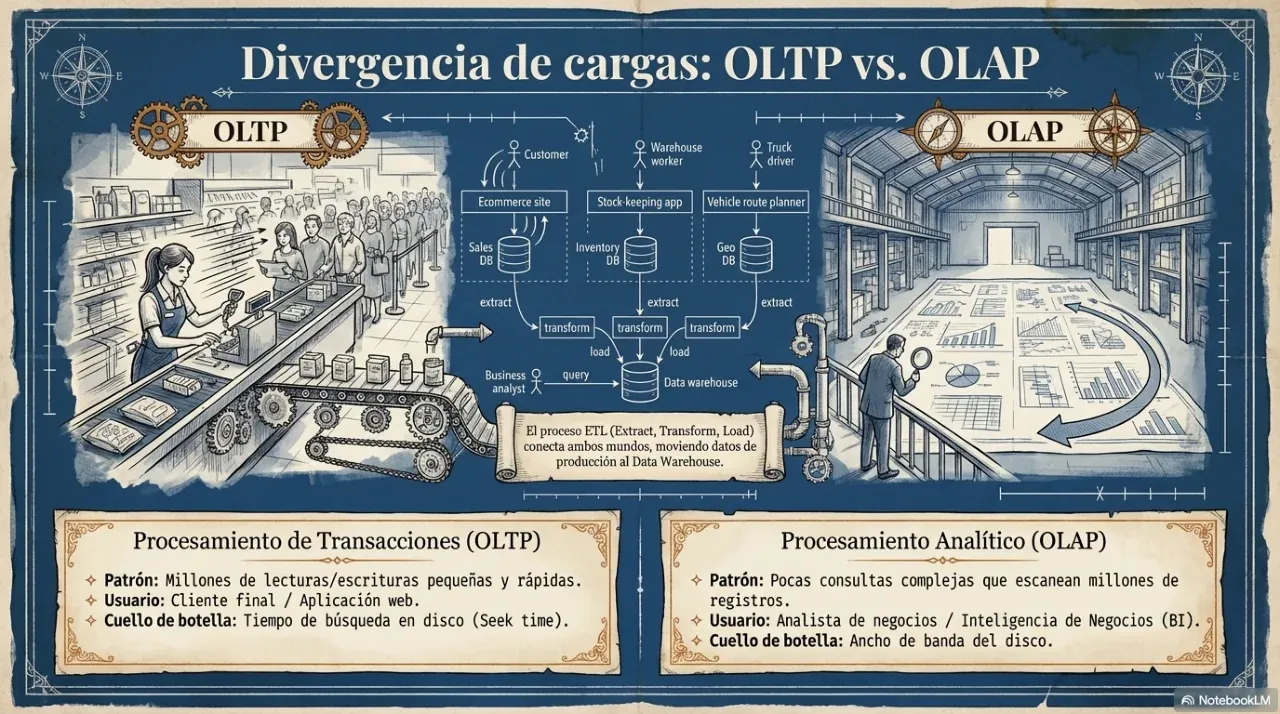
4. Procesamiento: batch vs. stream
Una vez que los datos están almacenados, hay que procesarlos. La pregunta es cuándo: ¿sobre datos acumulados o sobre eventos en tiempo real?
Procesamiento batch
Se ejecuta sobre un conjunto fijo de datos históricos. La latencia es alta (minutos u horas) pero el throughput es máximo. Ideal para reportes, análisis de tendencias y cualquier tarea que no requiera respuesta inmediata.
Herramientas: Apache Spark, dbt, Hadoop.
Procesamiento stream
Se ejecuta sobre eventos a medida que ocurren. La latencia es baja (milisegundos a segundos) pero el procesamiento es más complejo. Ideal para detección de fraude, alertas en tiempo real y pipelines de datos continuos.
Herramientas: Apache Kafka, Apache Flink, AWS Kinesis.
5. Comparativa de tecnologías por caso de uso
La siguiente tabla sintetiza las decisiones arquitectónicas más comunes y las tecnologías recomendadas para cada escenario de negocio.
| Caso de uso | Dimensión crítica | Modelo recomendado | Tecnología de referencia | Por qué no la alternativa |
|---|---|---|---|---|
| Procesamiento de pagos / cobros | Consistencia ACID | Relacional (SQL) | PostgreSQL | NoSQL sin transacciones puede generar cobros duplicados o stock negativo |
| Perfil de usuario con campos variables | Flexibilidad de esquema | Documentos (NoSQL) | MongoDB | SQL requiere migraciones costosas cada vez que se agrega un campo nuevo |
| Carrito de compras en Black Friday | Alta disponibilidad | Leaderless | Cassandra / DynamoDB | Single-leader rechaza escrituras si el líder está caído → ventas perdidas |
| Panel de control financiero / saldo de cuenta | Consistencia estricta de lectura | Single-leader | PostgreSQL con réplica de lectura | Leaderless puede mostrar saldo desactualizado al usuario |
| Reporte de ventas mensuales | Alto throughput sobre datos históricos | Batch | Apache Spark / dbt | Stream es innecesariamente complejo para datos que no cambian durante la consulta |
| Detección de fraude con tarjeta | Latencia sub-segundo | Stream | Apache Kafka + Flink | Batch solo detecta el fraude horas después, cuando el daño ya está hecho |
| Catálogo de productos con categorías distintas | Atributos dinámicos por registro | Documentos (NoSQL) | MongoDB | SQL requiere tablas de atributos EAV complejas y lentas |
| Dashboard de métricas sobre millones de eventos | Lectura de pocas columnas, muchas filas | Columnar | ClickHouse / BigQuery | Relacional escanea filas completas aunque solo necesites 2 columnas |
| Logs y auditoría de eventos | Escritura append-only, lectura ocasional | Stream + almacenamiento frío | Kafka → S3 / GCS | Base de datos relacional se llena y degrada con millones de registros de log |
| Agenda de turnos con confirmaciones | Consistencia + disponibilidad moderada | Relacional con caché | PostgreSQL + Redis | NoSQL introduce complejidad de conflictos innecesaria para volúmenes bajos |
6. Preguntas frecuentes
¿Qué es el teorema CAP y por qué importa al diseñar un sistema?
El teorema CAP establece que, cuando ocurre una partición de red —es decir, cuando dos nodos del sistema no pueden comunicarse—, solo es posible garantizar una de dos cosas: consistencia (todos los nodos ven el mismo dato al mismo tiempo) o disponibilidad (el sistema sigue respondiendo aunque no tenga el dato más reciente).
La decisión no es técnica sino de negocio. Un sistema bancario elige consistencia: prefiere devolver un error antes que mostrar un saldo incorrecto. Un carrito de compras elige disponibilidad: prefiere guardar el producto aunque un nodo esté caído y resolver el conflicto después.
¿Cuándo tiene sentido aplicar sharding (particionamiento)?
Cuando el volumen de datos o la carga de consultas supera lo que un único servidor puede manejar, incluso con el hardware más potente disponible. El sharding divide los datos entre múltiples nodos según una clave de partición.
El riesgo principal es elegir mal esa clave: si todos los registros del mismo cliente van al mismo nodo, ese nodo se convierte en un “hot spot” y el resto del clúster queda subutilizado. Una buena clave de partición distribuye la carga de forma uniforme y evita que las consultas más frecuentes necesiten cruzar múltiples nodos.
¿Qué significa “consistencia eventual” y cómo explicársela a un cliente?
Significa que si se deja de escribir datos, eventualmente todos los nodos del sistema convergerán al mismo valor. No es inconsistencia permanente; es un retraso controlado de sincronización, típicamente de milisegundos a segundos.
Para un cliente: “El cambio que hiciste ya está guardado de forma segura. Es posible que por unos segundos algunos usuarios vean el dato anterior, hasta que la actualización se propague a todos los servidores. Para la mayoría de los casos de uso esto es completamente aceptable.”
¿Por qué no se puede confiar ciegamente en los timestamps de los servidores?
Cada servidor tiene su propio reloj físico que tiende a adelantarse o atrasarse con el tiempo. En un sistema distribuido que usa timestamps para resolver conflictos del tipo “gana el último que escribió” (last write wins), un servidor con la hora mal configurada puede sobreescribir datos más nuevos con datos más viejos.
La solución son los relojes lógicos: contadores o vectores de versión que rastrean el orden causal de los eventos, independientemente del tiempo físico. No importa si el servidor A marcó su escritura a las 10:00:01 y el servidor B a las 10:00:00 si se sabe que B escribió causalmente después de A.
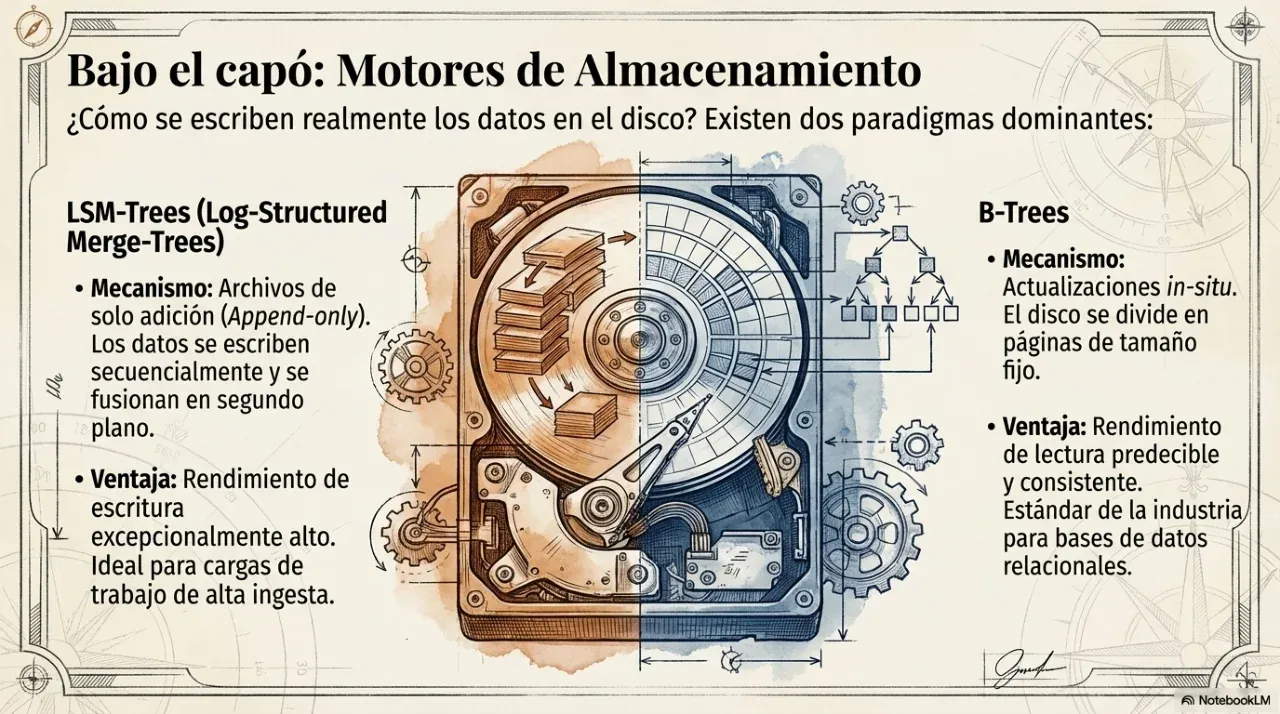
¿Cuándo conviene usar una base de datos en columnas en lugar de una relacional?
Cuando la consulta típica necesita agregar (sumar, promediar, contar) una o dos columnas sobre millones o miles de millones de filas. Una base de datos relacional almacena los datos fila por fila: para leer solo la columna “precio” tiene que cargar toda la fila en memoria. Una base columnar almacena cada columna por separado, lo que reduce drásticamente el I/O y acelera las consultas analíticas entre 10x y 100x para este patrón de acceso.
El costo es que las escrituras fila por fila son más lentas. Por eso el almacenamiento columnar es ideal para analítica (muchas lecturas, pocas escrituras) y no para sistemas transaccionales (muchas escrituras, lecturas por clave primaria).
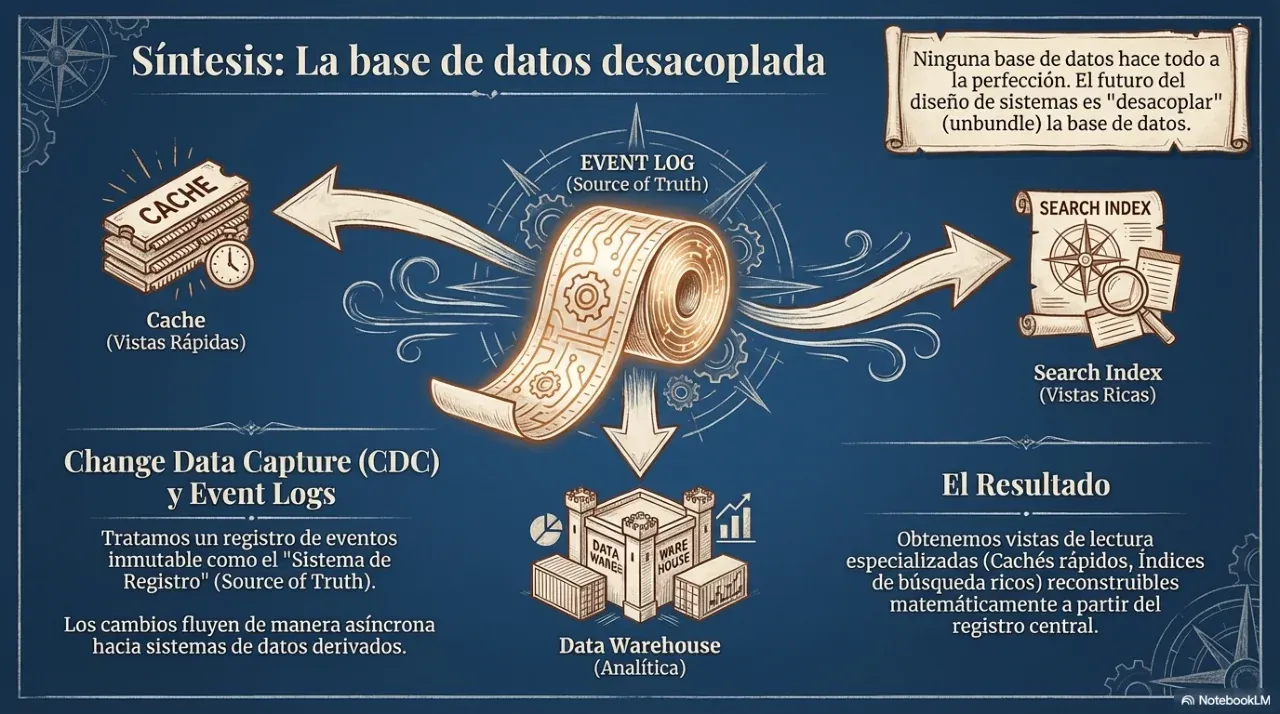
¿Kafka es una base de datos?
No exactamente, pero tampoco es solo una cola de mensajes. Kafka es un log de eventos distribuido y persistente: los mensajes no se eliminan al ser consumidos sino que se retienen durante un período configurable. Esto permite que múltiples consumidores independientes los lean a su propio ritmo, que un consumidor nuevo pueda “rebobinar” y reprocesar el historial, y que el sistema funcione como fuente de verdad para derivar múltiples vistas de los datos.
Esta característica —la inmutabilidad del log— es lo que lo convierte en la columna vertebral de arquitecturas event-driven como la que describe el roadmap de este proyecto.
7. Siguiente paso
El primer paso no es elegir tecnologías: es mapear qué dimensión es la crítica para tu caso (consistencia, disponibilidad o latencia de procesamiento).
Podemos hacer ese análisis juntos. Escribinos por WhatsApp o por email y arrancamos con un diagnóstico sin costo.
Fuentes y referencias
- Designing Data-Intensive Applications — Martin Kleppmann (2017)