Diseñar sistemas a escala: la guía definitiva de microservicios
De los principios de Sam Newman al código real. Qué son, para qué sirven, cuándo no usarlos y qué patrones de diseño separan una arquitectura que escala de una que colapsa.

1 / 13
Hay una pregunta que aparece siempre que un sistema empieza a crecer: ¿cuándo dejo de agregar código al monolito y empiezo a dividirlo? La respuesta honesta es que la mayoría de los equipos lo hacen demasiado tarde o, peor, demasiado pronto.
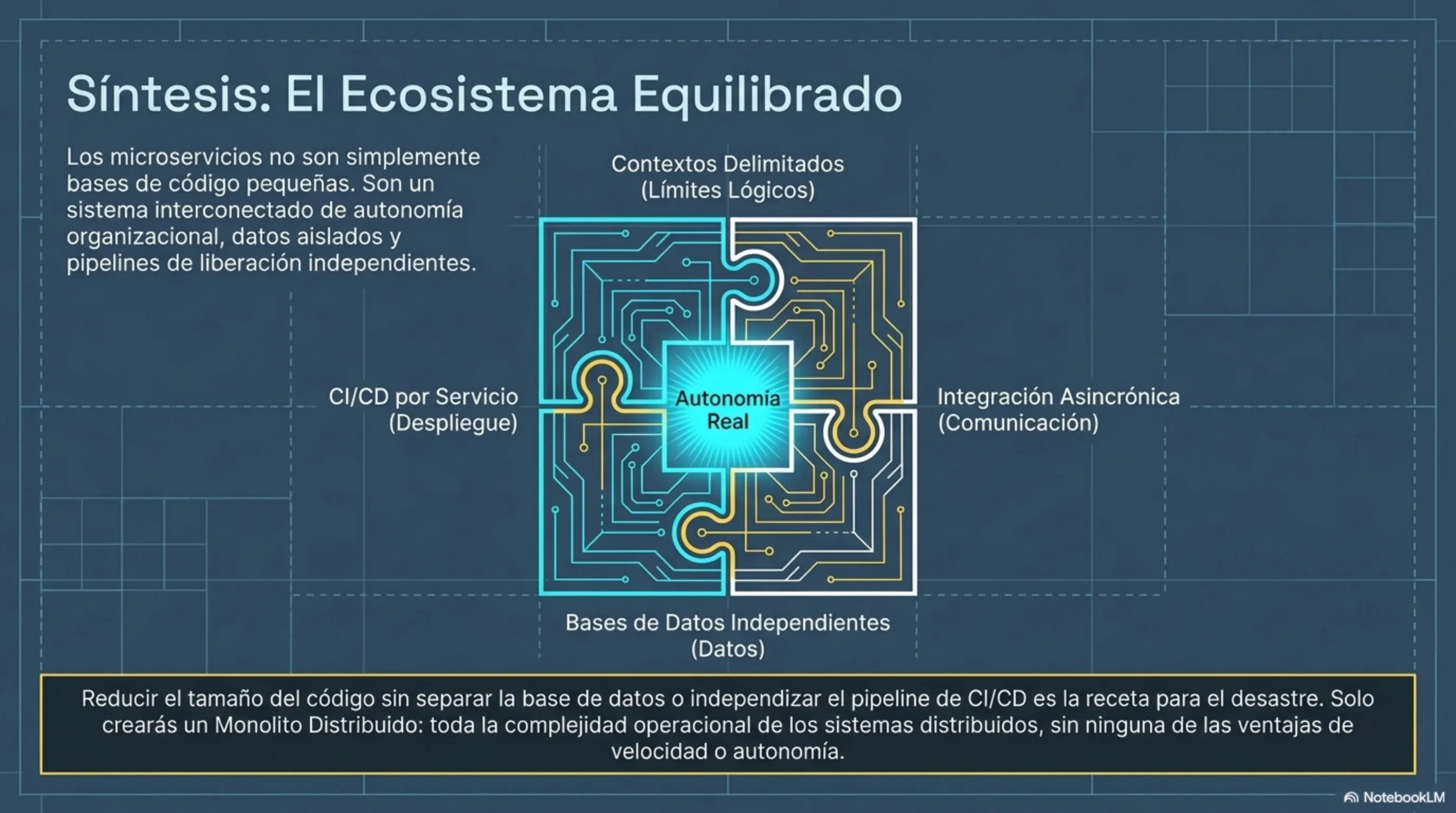
Los microservicios no son una arquitectura. Son una decisión organizacional que tiene consecuencias técnicas. Si no entendés eso antes de escribir la primera línea, vas a construir un monolito distribuido: lo peor de los dos mundos.
Esta guía condensa cuatro pasadas de análisis crítico sobre “Building Microservices” de Sam Newman y experiencia aplicada. No es un resumen del libro. Es una destilación completa de todo lo que importa cuando tenés que tomar decisiones reales.
Qué son los microservicios y cuáles son sus características fundamentales
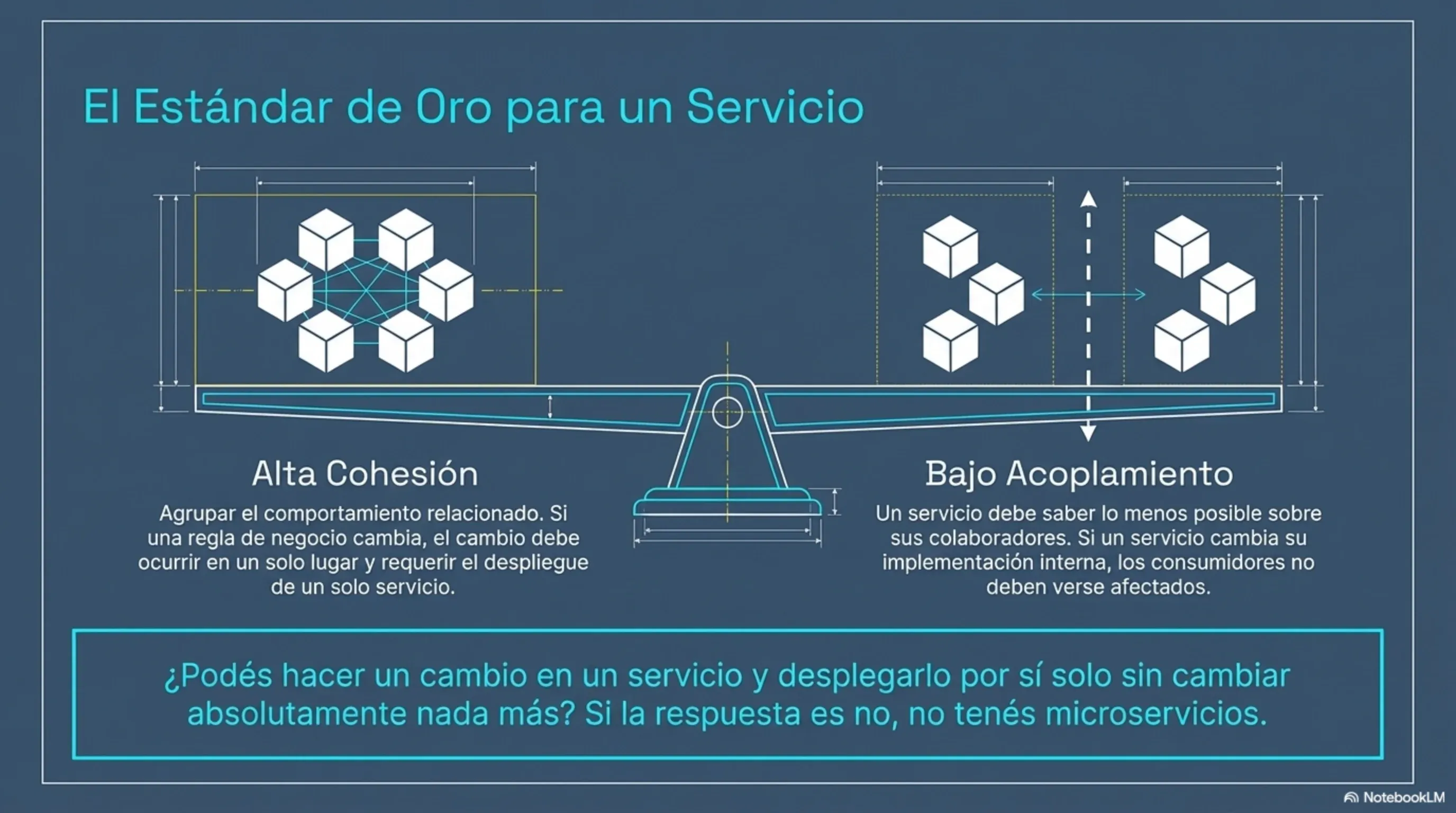
Los microservicios son servicios autónomos, pequeños y enfocados en realizar una sola tarea. No es una definición de marketing: es una restricción de diseño. Cada servicio tiene su propio ciclo de vida, su propio repositorio, su propio pipeline de despliegue y su propia base de datos.
Las ventajas que justifican esa complejidad adicional son concretas:
- Heterogeneidad tecnológica: cada equipo puede elegir el lenguaje y la base de datos que mejor resuelven su problema específico. El servicio de búsqueda puede usar Elasticsearch; el de transacciones, PostgreSQL; el de sesiones, Redis. No hay un mandato tecnológico global.
- Resiliencia por aislamiento de fallos: cuando un servicio falla, el resto del sistema puede seguir operando. Si el servicio de recomendaciones está caído, los usuarios todavía pueden comprar. En un monolito, un error no manejado puede tumbar todo.
- Escalabilidad específica: podés escalar solo el componente que está bajo presión. Si el servicio de procesamiento de pagos necesita diez instancias en el pico de fin de mes, lo escalás solo a él, sin pagar el costo de escalar todo el sistema.
- Facilidad de despliegue independiente: un equipo puede liberar su servicio sin coordinar con todos los demás. Esto acelera dramáticamente la velocidad de entrega.
El error más caro: descomponer sin entender el dominio
Newman lo dice sin rodeos: si no entendés bien tu dominio de negocio, no uses microservicios. Construí primero un monolito. Aprendé dónde están las fronteras naturales. Después dividí.
Una descomposición prematura genera lo que los arquitectos llaman chatty services: servicios que se llaman entre sí en cada operación, con latencias acumuladas y sin la cohesión que justifica la separación. El costo de refactorizar una arquitectura mal dividida es exponencialmente mayor que refactorizar un monolito.
La heurística de Newman para el tamaño correcto: un servicio debería poder ser reescrito por un equipo pequeño en no más de dos semanas. Si lleva más, está haciendo demasiado. Si lleva menos de un día, probablemente no justifica el overhead de ser un servicio independiente.
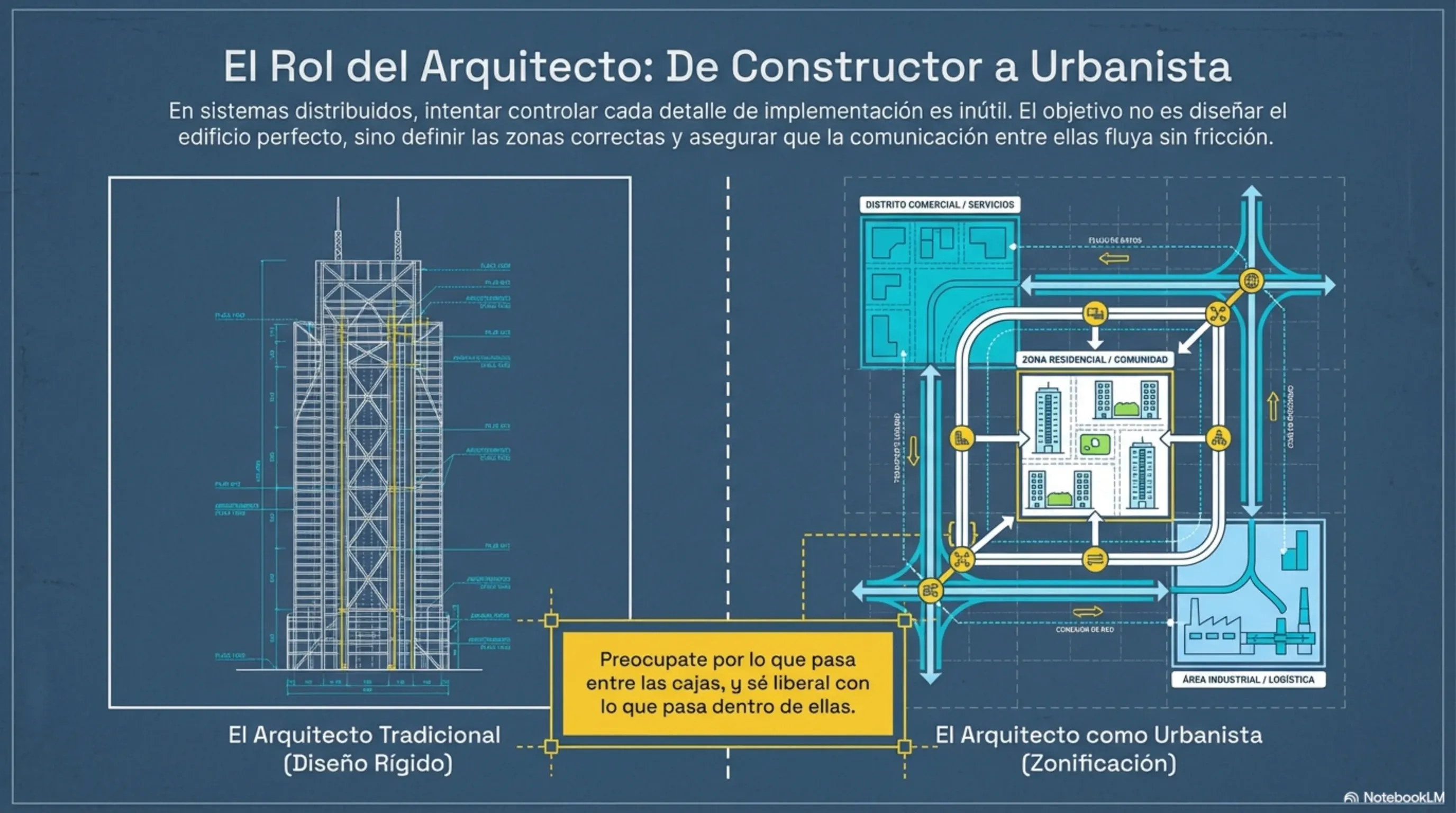
El rol del arquitecto: de ingeniero a urbanista
En un ecosistema de microservicios, el rol del arquitecto cambia radicalmente. Ya no es el responsable de diseñar cada componente interno ni de generar diagramas cerrados al inicio del proyecto. Pasa a ser, en palabras de Newman, un urbanista: alguien que define las zonas, las rutas de interacción y los estándares de convivencia, pero que delega las decisiones de detalle a cada equipo.
Lo que el arquitecto evolutivo controla con rigor son los puntos donde los servicios interactúan entre sí: los estándares de comunicación (HTTP, mensajería), el formato de los logs, la estrategia de monitoreo centralizado. Lo que deliberadamente no controla es la tecnología interna de cada servicio: qué lenguaje usa, qué base de datos elige, cómo organiza su código interno.
Esta delegación es la que hace posible la heterogeneidad tecnológica. Y es también lo que exige madurez organizacional: los equipos deben poder tomar decisiones de calidad sin que alguien les diga qué hacer en cada paso.
Cómo encontrar las fronteras correctas: Bounded Contexts y DDD
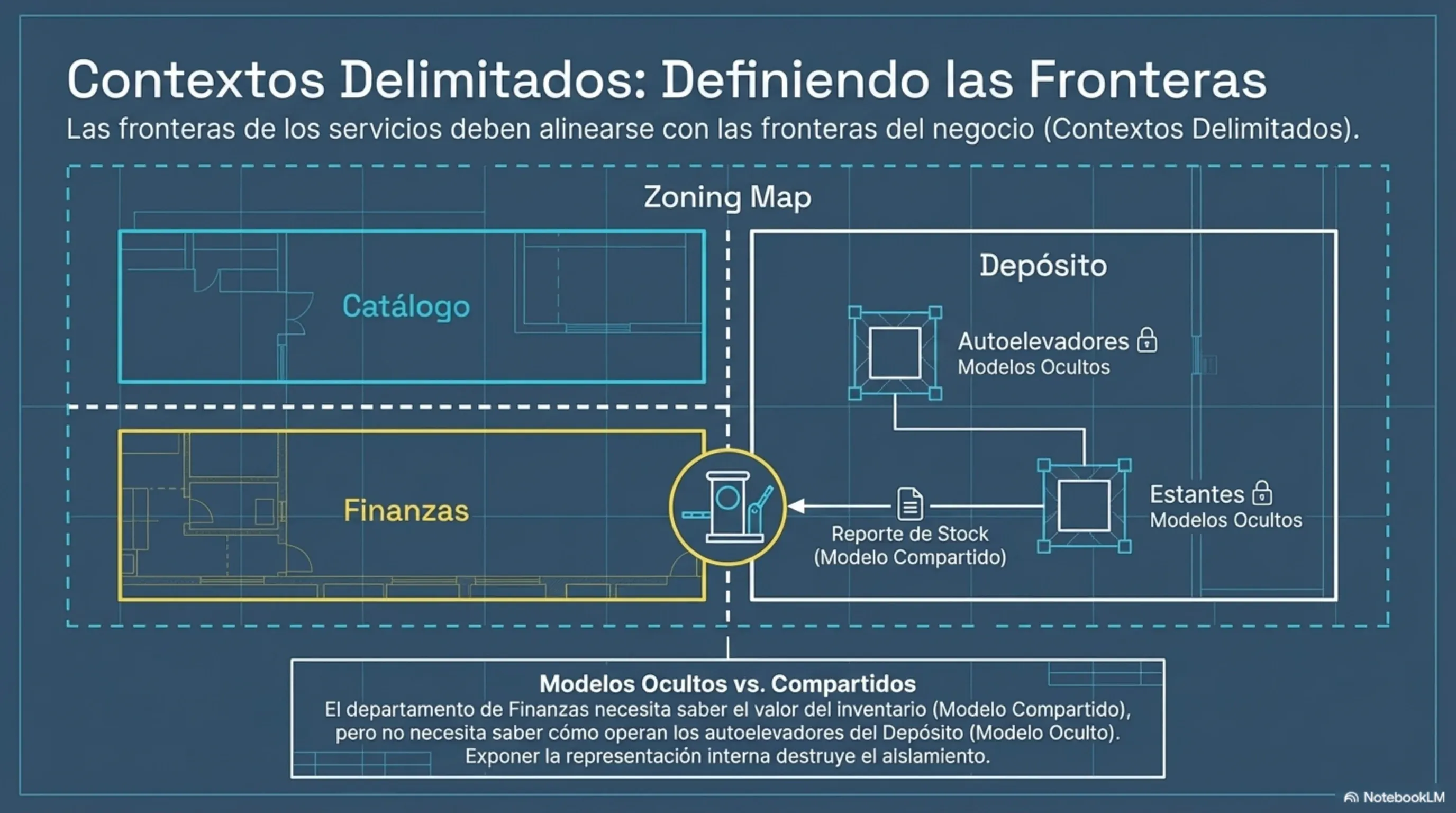
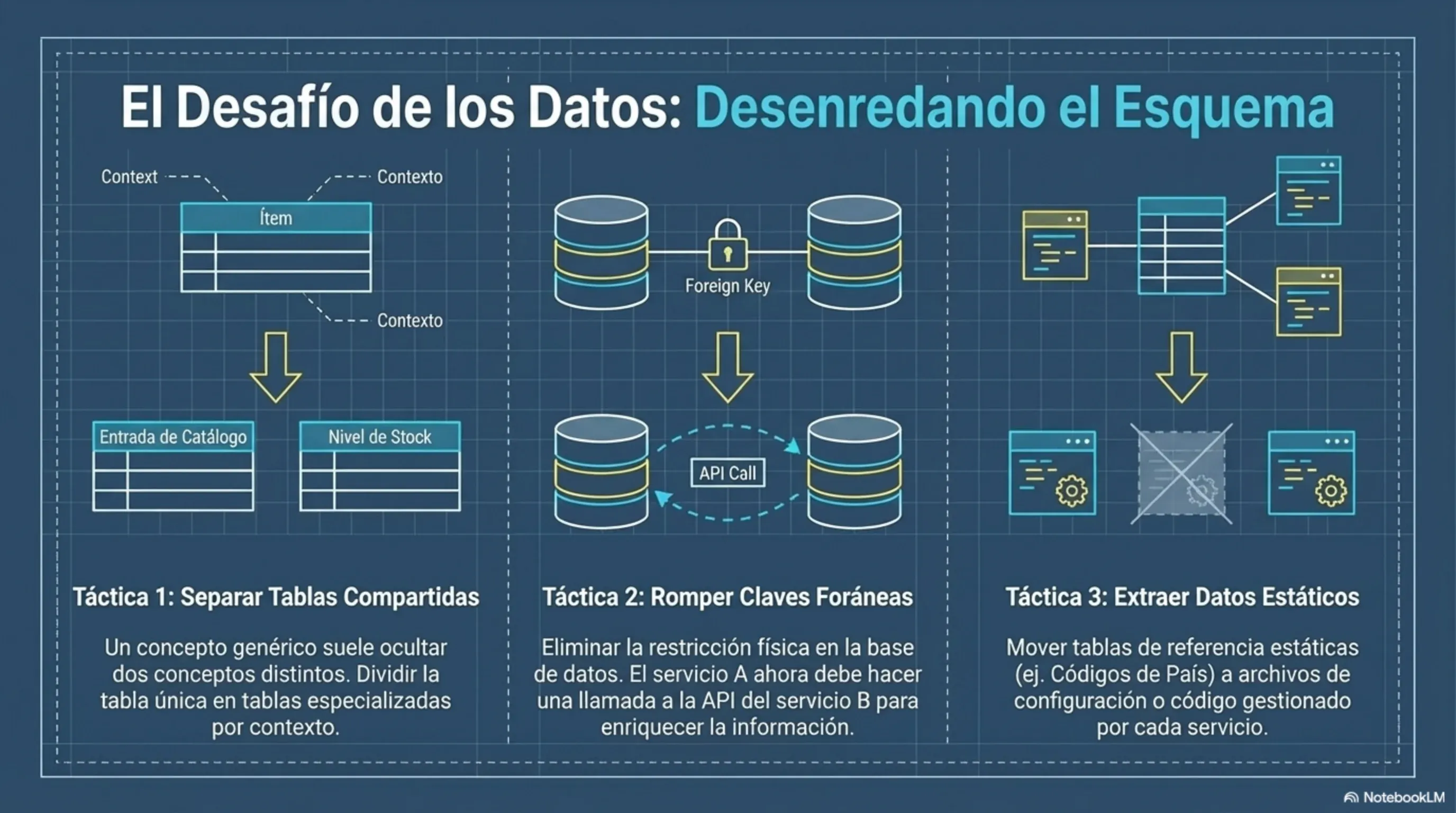
El concepto más valioso que el libro toma prestado de Domain-Driven Design (DDD) es el de Bounded Context (contexto delimitado). Un bounded context es una frontera semántica dentro de la cual un modelo de negocio tiene significado consistente.
Ejemplo concreto: la palabra “cliente” significa cosas distintas en el área de ventas (un lead con probabilidad de conversión), en facturación (un sujeto legal con CUIT) y en soporte (un ticket abierto con historial). Si construís un único servicio ClienteService que intenta satisfacer a los tres, terminás con un objeto anémico lleno de campos opcionales que nadie entiende.
La solución correcta es tres servicios separados con sus propios modelos de Cliente, cada uno dueño de su propia base de datos. Cuando ventas necesita saber si un cliente ya tiene facturas, le pregunta al servicio de facturación por su API, no comparte la tabla.
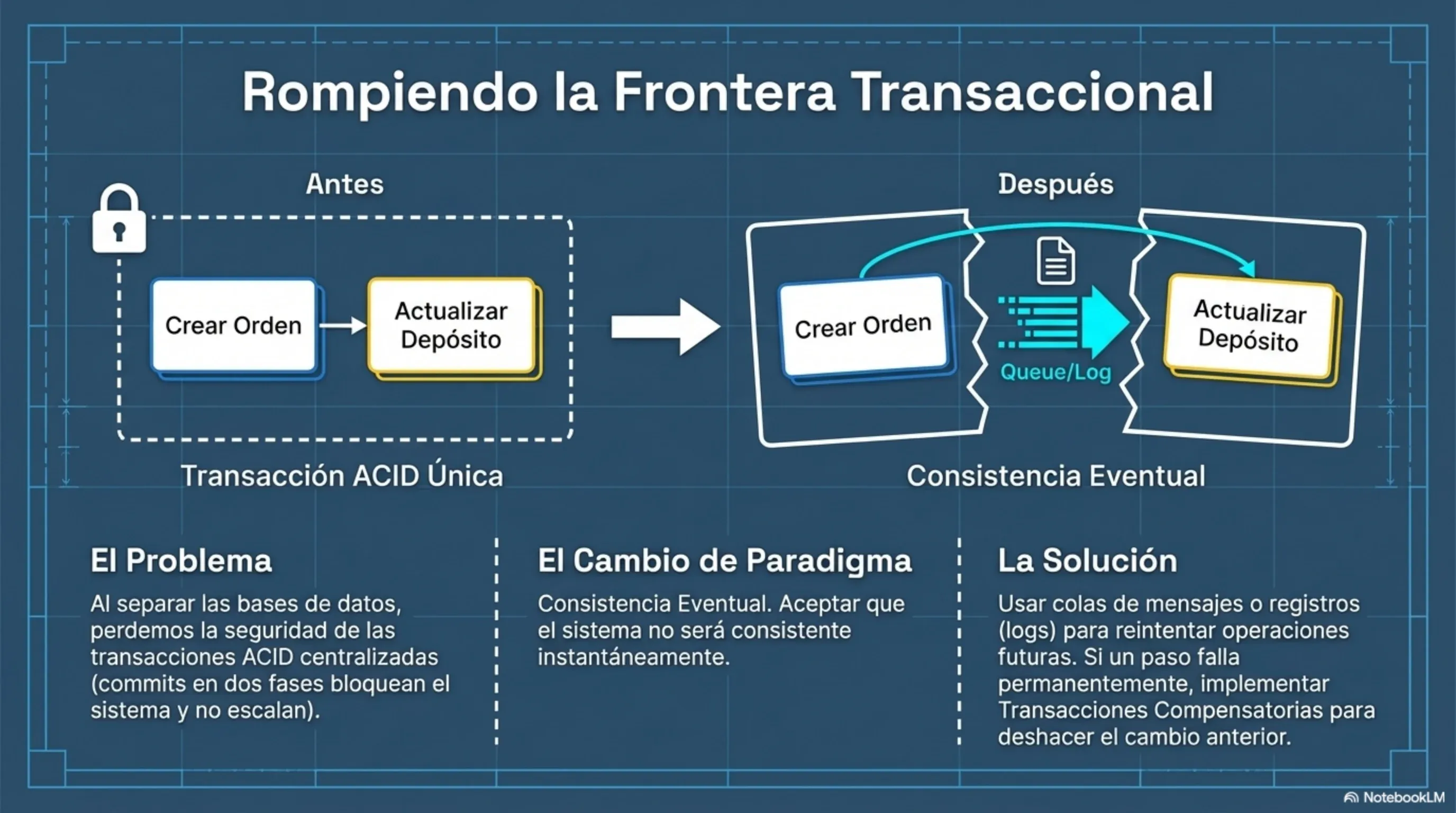
Regla inviolable de Newman: cada microservicio es el único dueño de sus datos. Ningún otro servicio toca su base de datos directamente. Jamás. Compartir una base de datos entre distintos microservicios destruye el encapsulamiento y expone las estructuras internas de datos, creando un sistema altamente acoplado y frágil. Modificar un esquema de la base de datos podría colapsar a los múltiples consumidores, forzando un despliegue sincronizado masivo y propagando la lógica de negocio fragmentada hacia afuera del servicio.
Contextos anidados
DDD también permite subdivisión progresiva. Newman recomienda comenzar con contextos delimitados genéricos de gran tamaño y, a medida que la necesidad técnica y organizativa lo pida, subdividirlos en microservicios anidados que permanezcan ocultos al exterior. Por ejemplo, un macro-servicio “Almacén” puede estar compuesto internamente por “Gestión de inventario” y “Recepción de bienes”, sin que los servicios externos necesiten saber esa distinción. Los detalles internos quedan encapsulados; solo la interfaz pública importa.
El flujo de datos: entrada, proceso y salida
Para entender cómo fluye la información en un ecosistema de microservicios, conviene pensar en cada servicio como una máquina de estados autónoma que gestiona flujos de información fuertemente orientados hacia capacidades de negocio.
Entrada
Hay dos formas de recibir trabajo:
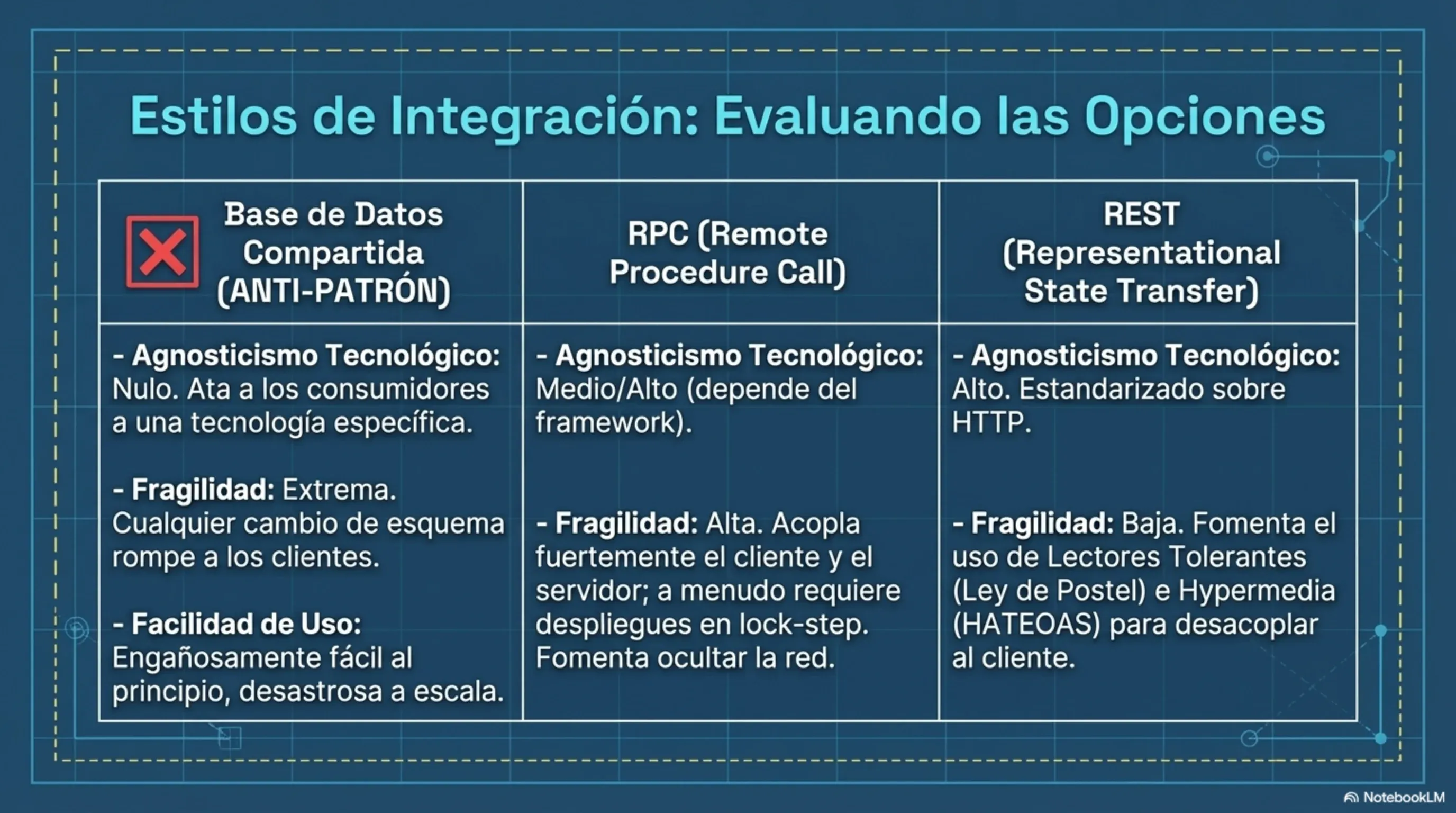
- Sincrónica (HTTP/REST): el cliente hace un
POST /pedidosy espera la respuesta. Es simple, trazable y directo. El problema es que crea acoplamiento temporal: si el servicio de pedidos está caído, el cliente falla. Newman recomienda REST sobre RPC porque aprovecha las capacidades inherentes de la red (verbos, proxies y recursos limpios). Los enfoques tipo RPC como Java RMI tienden a empaquetar librerías que acoplan al cliente con el servidor y ocultan falsamente las fallas de red haciéndolas parecer llamadas a métodos locales. - Asincrónica (eventos): el cliente publica un evento
PedidoSolicitadoen una cola (RabbitMQ, Kafka) y sigue adelante. El servicio de pedidos lo procesa cuando puede. Es más resiliente y desacopla temporalmente a los servicios, pero exige mayor sofisticación en el rastreo y reintento de fallos.
Proceso
El servicio no debería ser un wrapper de CRUD. Debería exponer intenciones de negocio: AprobarPedido(), CancelarPedido(), AplicarDescuento(). Newman desaconseja totalmente los servicios anémicos que solo envuelven operaciones de base de datos sin lógica propia. La lógica que diferencia tu negocio vive acá, encapsulada, sin filtrarse hacia los consumidores.
Salida
Después de procesar, el servicio tiene dos responsabilidades de salida:
- Devolver la respuesta inmediata al solicitante (si era sincrónico), idealmente usando HATEOAS: hipervínculos incluidos en la respuesta que dictan al cliente qué otras operaciones y estados están disponibles a continuación, abstrayendo las URI reales.
- Publicar un evento al bus (
PedidoAprobado,StockActualizado) para que otros servicios reaccionen sin que este servicio sepa quiénes son ni cuántos son.
La respuesta nunca debería exponer el modelo de datos interno de la base de datos. Solo se expone un modelo externo: la representación que el servicio decide hacer pública.
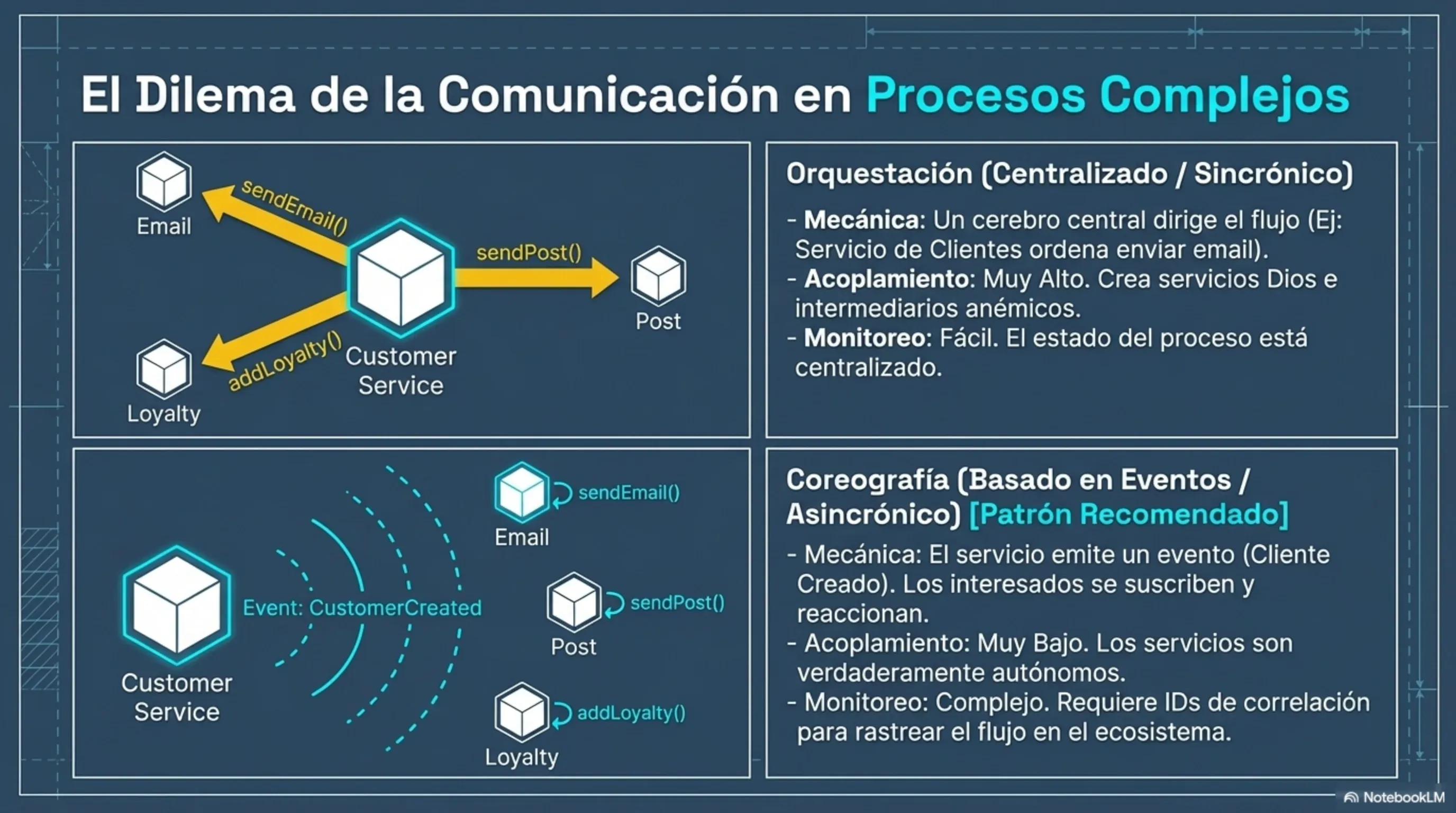
Orquestación vs. coreografía: la decisión que define tu arquitectura
Esta es probablemente la decisión de diseño más importante de todo el sistema.
Orquestación: existe un servicio “director” que sabe el orden de los pasos y le dice a cada servicio qué hacer. La lógica está codificada explícitamente en un único punto, lo que facilita visualizar el flujo de negocio e identificar fallos transaccionales. El problema es que ese director termina conociéndolo todo y convirtiéndose en el nuevo monolito, rodeado de servicios anémicos que perdieron su lógica de negocio.
Coreografía: cada servicio conoce solo su propia responsabilidad y reacciona a eventos. Cuando el servicio de pagos publica PagoConfirmado, el servicio de envíos lo escucha y empieza a preparar el paquete. Nadie le dijo que lo hiciera: simplemente sabe que ese es su trabajo cuando ese evento ocurre. Este modelo provee un nivel excelente de desacoplamiento y autonomía, ideal para el crecimiento independiente por parte de cada equipo.
Newman recomienda enfáticamente la coreografía. El costo: necesitás invertir en Correlation IDs y en herramientas de monitoreo distribuido. Sin eso, depurar un error en un sistema coreografiado es prácticamente imposible.
Versionado de APIs: cómo cambiar sin romper a tus consumidores
En un ecosistema distribuido, los cambios de API son una operación quirúrgica. Un cambio incompatible en un servicio puede romper silenciosamente a todos sus consumidores.
Newman recomienda aplicar la Ley de Postel: “Sé conservador en lo que haces, sé liberal en lo que aceptas de los demás”. Esto significa que el servicio debería poder tolerar campos adicionales en los mensajes que recibe sin fallar, y no debería eliminar campos de sus respuestas sin avisar con anticipación.
Cuando los cambios incompatibles son absolutamente necesarios, la técnica recomendada es coexistir endpoints: desplegar simultáneamente la versión antigua (V1) y la nueva (V2) en el mismo servicio en producción, dando tiempo a los consumidores para migrar sin presión. Esto se complementa con versionado semántico (MAJOR.MINOR.PATCH): un cambio en MAJOR indica ruptura de compatibilidad; un cambio en MINOR o PATCH es retrocompatible.
El peligro del DRY en sistemas distribuidos
“Don’t Repeat Yourself” es un principio valioso en un monolito. En microservicios puede ser peligroso.
Compartir código mediante librerías centralizadas o librerías de clientes (SDKs) creadas por el mismo equipo del servidor tiende a filtrar la lógica de negocio al cliente, provocando acoplamiento duro y forzando despliegues en conjunto. Si el SDK del servicio de pagos cambia, todos los consumidores que lo usan deben actualizar y redesplegar al mismo tiempo. Eso destruye la autonomía.
La alternativa que Newman prefiere son los Service Templates (chasis de microservicios): herramientas como Dropwizard o Karyon que arrancan un servicio nuevo con las políticas transversales ya incorporadas —formateo de logs a JSON centralizado, recolección de métricas, health checks— pero dejando la lógica de negocio completamente libre e independiente. El gobierno técnico se aplica a través de la plantilla, no a través de librerías compartidas.
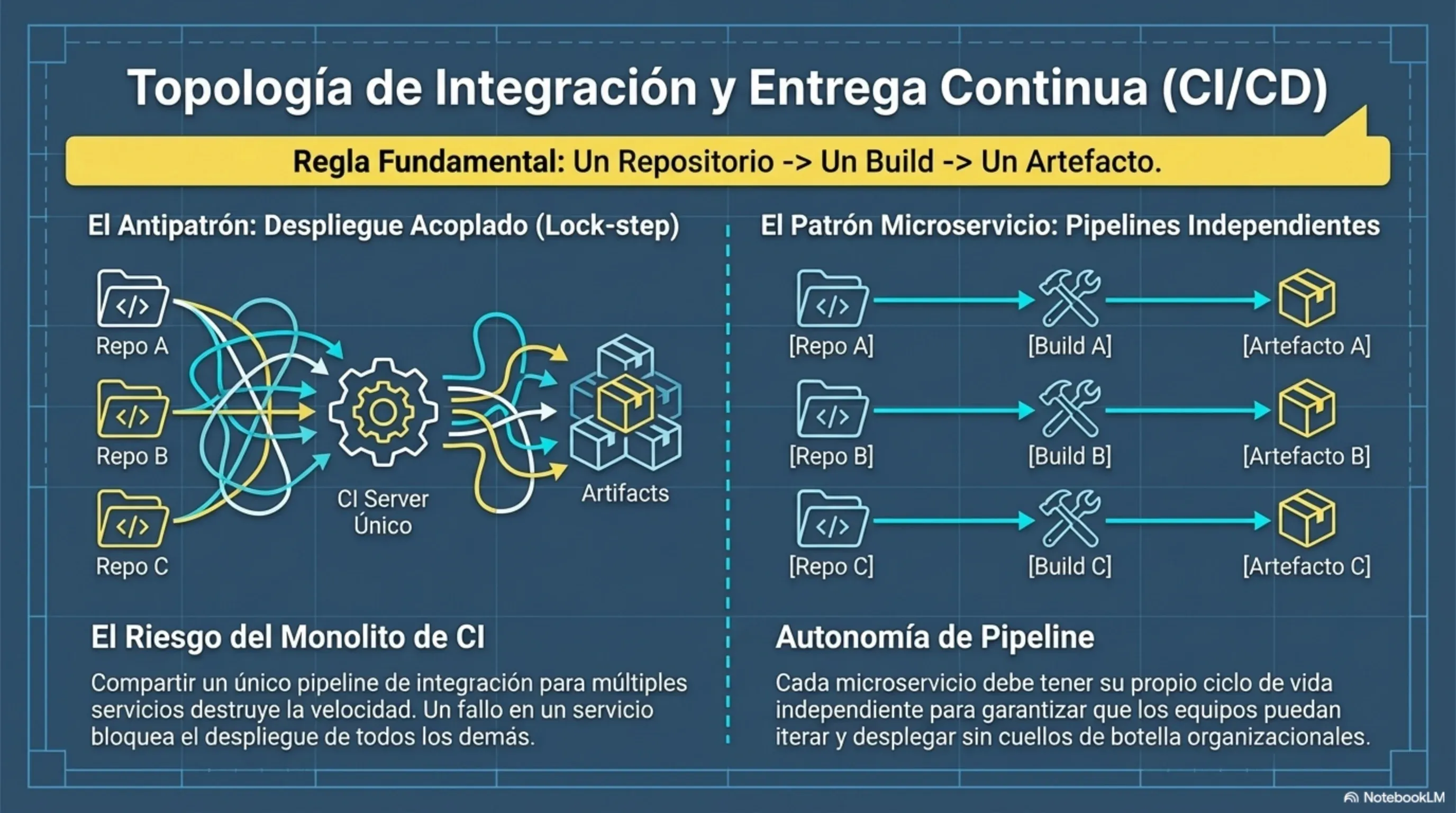
CI/CD: un pipeline por servicio, sin excepción
Para que la autonomía de los microservicios sea real y no solo nominal, la regla es un microservicio por pipeline de construcción. Si dos servicios comparten un pipeline, su despliegue está acoplado y la independencia es una ilusión.
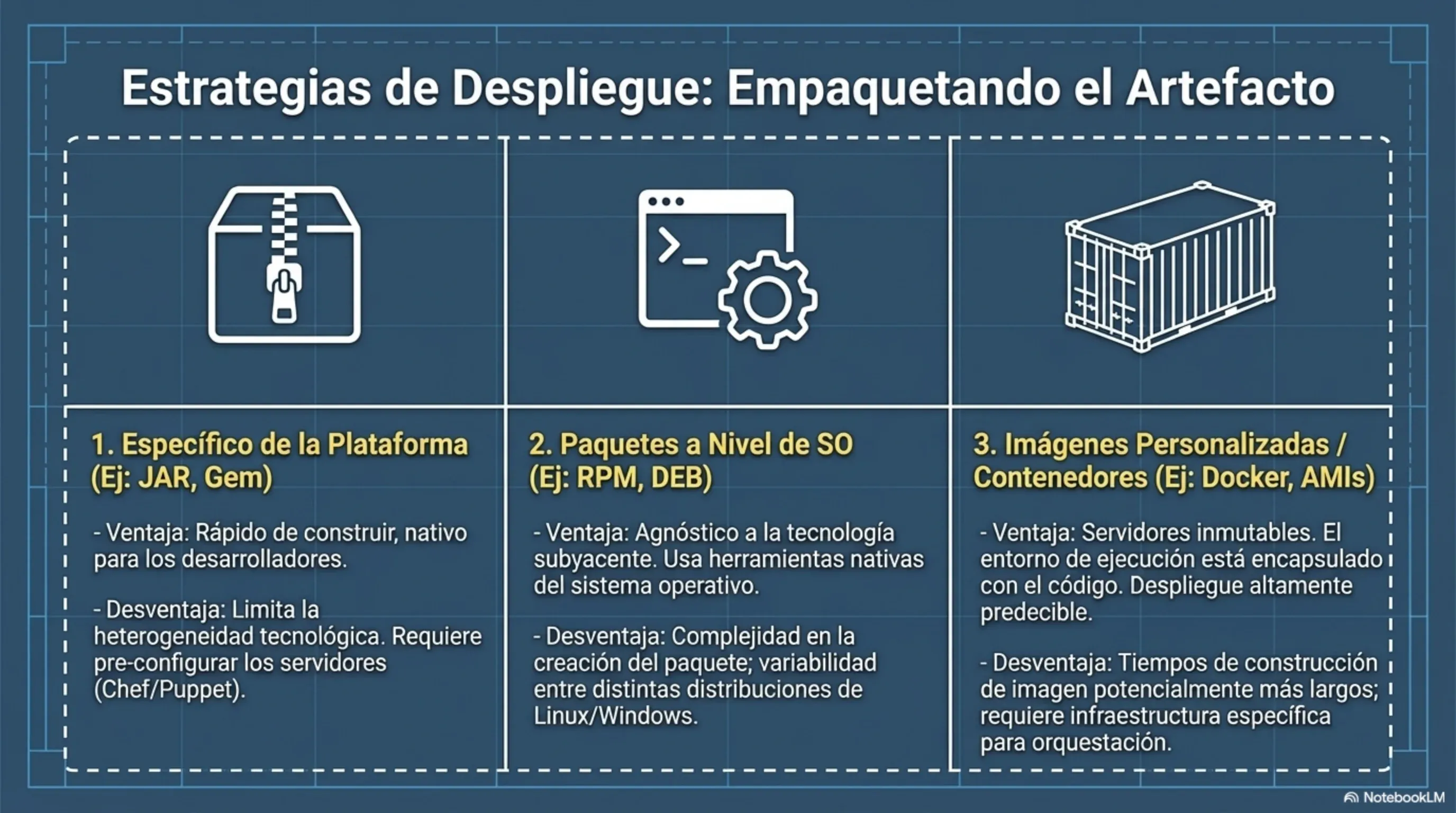
En cuanto a infraestructura, Newman aconseja tender a un modelo de un servicio por host o, mejor aún, contenedores basados en Docker. Docker encapsula la aplicación y su entorno completo, aislando la complejidad técnica y facilitando el uso de servidores inmutables: en lugar de actualizar un servidor en producción, se reemplaza por uno nuevo con la versión correcta. Esto simplifica la seguridad, facilita el rollback y elimina los efectos colaterales entre servicios que comparten infraestructura.
Los patrones que no podés ignorar
Strangler Fig (el estrangulador)
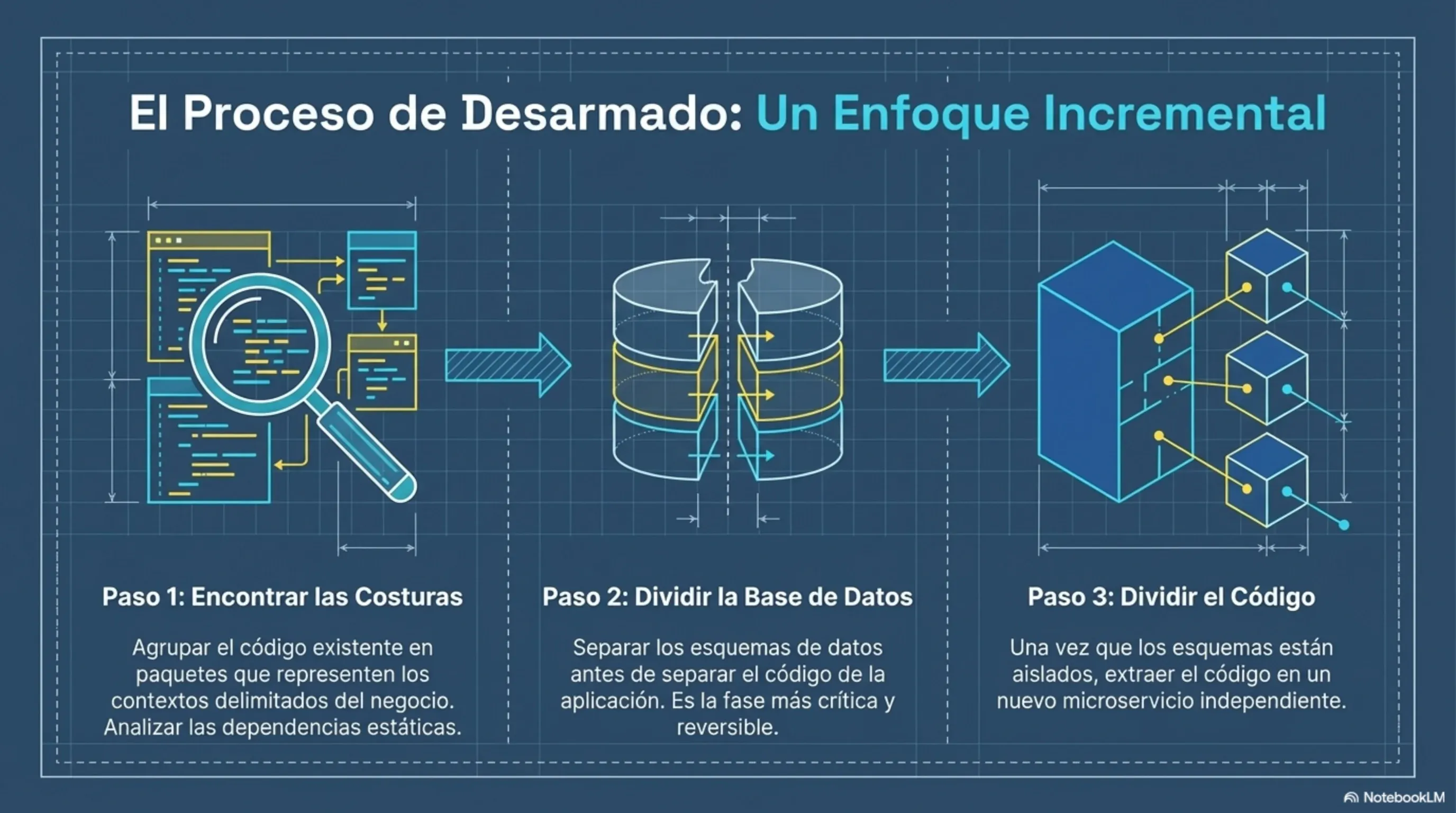
Si tenés un monolito en producción —y la mayoría de los proyectos reales tienen uno—, no lo reescribas de cero. Ese es el camino al fracaso conocido como “Big Bang rewrite”.
El patrón Strangler consiste en interceptar las llamadas al monolito en su frontera exterior (un proxy, un API Gateway) y redirigir gradualmente funcionalidades específicas a microservicios nuevos. El monolito viejo sigue corriendo, pero va perdiendo responsabilidades hasta que se puede apagar. Es más lento. También es el único enfoque que tiene tasa de éxito razonable en producción.
Circuit Breaker
Un servicio que depende de otro hereda su fragilidad. Si el servicio de notificaciones tarda 30 segundos en responder, tu servicio de pedidos también tarda 30 segundos. Con 100 pedidos simultáneos, tenés 100 hilos esperando una respuesta que quizás nunca llegue.
El circuit breaker detecta un número configurable de fallos consecutivos y “abre el circuito”: en lugar de intentar llamar al servicio caído, devuelve inmediatamente un error o un fallback predefinido. Después de un tiempo, intenta una llamada de prueba (estado HALF_OPEN). Si la prueba pasa, cierra el circuito; si no, lo mantiene abierto.
Junto con timeouts y bulkheads (aislamiento de pools de recursos por servicio), forman lo que Newman llama las “medidas de seguridad arquitectónica”: el conjunto mínimo que separa un sistema que falla graciosamente de uno que falla catastróficamente.
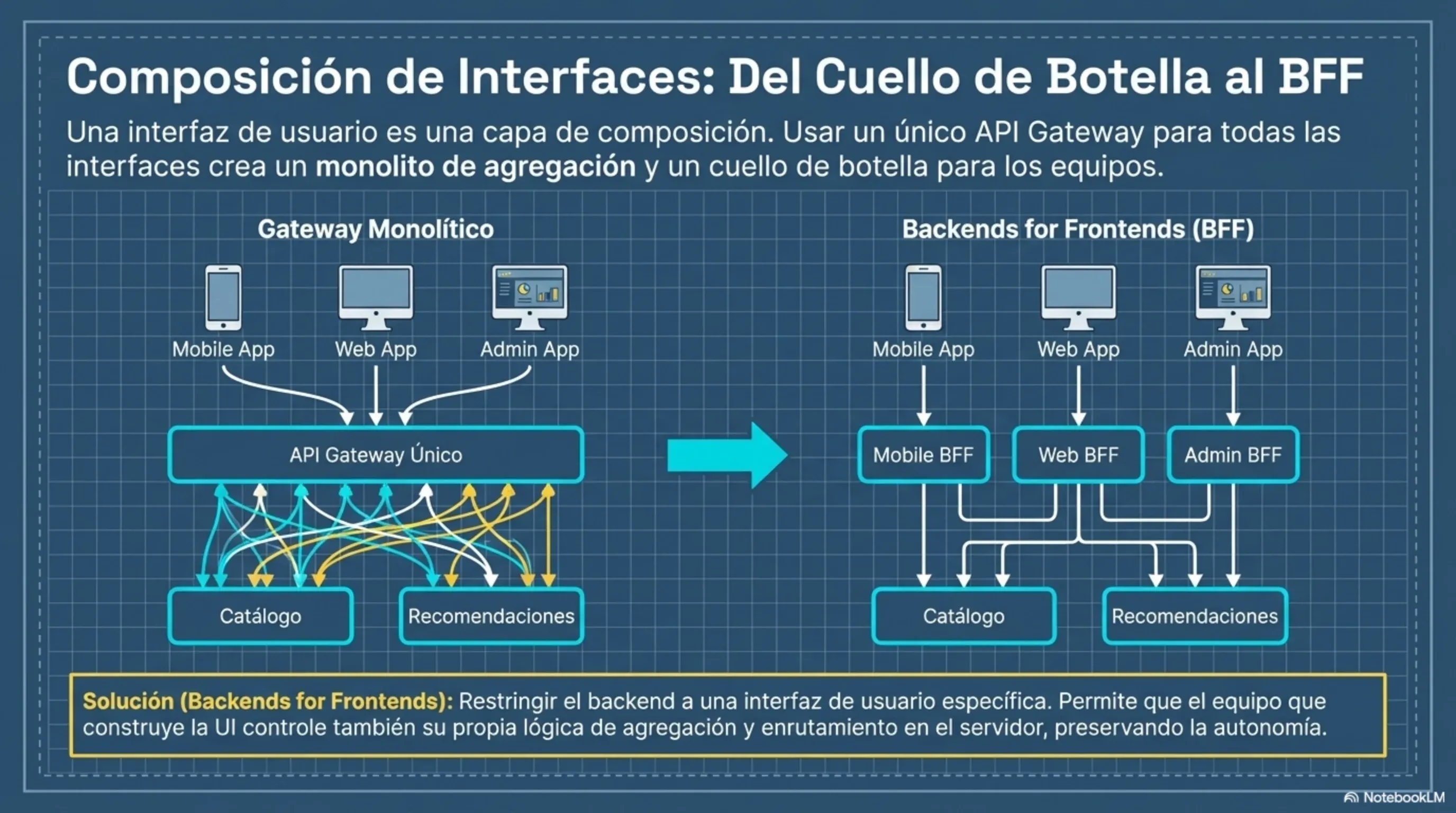
Backend for Frontend (BFF)
Una sola API diseñada para satisfacer a una app móvil, una web de escritorio y una API pública al mismo tiempo termina siendo mediocre para todos. El patrón BFF propone crear un servicio de fachada por tipo de cliente. El “Mobile BFF” llama a los microservicios internos, filtra, reduce los payloads para no agotar datos móviles ni batería, y devuelve exactamente lo que la app necesita. Si cambian los requisitos del móvil, solo cambia el Mobile BFF, sin tocar nada interno.
CQRS (Command Query Responsibility Segregation)
Para reportes y dashboards analíticos, hacer JOINs entre bases de datos de distintos microservicios destruye el rendimiento y viola la separación de datos. CQRS resuelve esto creando un modelo de lectura separado.
Un microservicio de reportes escucha todos los eventos relevantes del sistema (PedidoCreado, ClienteActualizado, StockModificado) y mantiene su propia base de datos desnormalizada y optimizada para lectura. Los dashboards consultan solo esta base, sin tocar los servicios transaccionales. Los comandos van a los servicios de escritura; las consultas van al modelo de lectura.
Composición de UI por fragmentos
Además de la clásica agregación de datos por API, existe la composición por fragmentos de UI. En este patrón, los microservicios renderizan directamente partes de la interfaz web —el módulo de “Recomendaciones”, el de “Historial de compras”— y el portal principal actúa como un marco que amalgama estos componentes pre-renderizados. Cada equipo controla su fragmento de UI de punta a punta, sin depender de un equipo de frontend centralizado.
Service discovery: cómo los servicios se encuentran entre sí
En un sistema distribuido donde los servicios pueden moverse entre hosts y escalar dinámicamente, no podés hardcodear IPs. Necesitás un mecanismo de descubrimiento.
DNS: es el estándar global, cualquier tecnología sabe resolverlo. El problema es el caché: cuando una instancia de servicio falla o cambia de IP, los clientes pueden seguir enviando tráfico a la dirección muerta durante varios minutos hasta que el TTL expire.
Registros dinámicos (Consul, Eureka, Zookeeper): mantienen un directorio en tiempo real de qué servicios están sanos y en qué puertos están corriendo. Si un nodo cae, es removido del registro en milisegundos, re-enrutando el tráfico automáticamente. El costo es que introducen una nueva pieza de infraestructura central de misión crítica: si el registro de servicios cae, el sistema distribuido no puede funcionar.
Testing: por qué las pruebas E2E no escalan
Las pruebas End-to-End en microservicios se vuelven frágiles y lentas. Requieren orquestar el despliegue de múltiples servicios simultáneamente, lo que genera interdependencias falsas, aumenta masivamente el tiempo de feedback y promueve compilaciones intermitentes (flaky tests).
Newman propone reemplazarlas progresivamente por Consumer-Driven Contracts (CDCs), usando herramientas como Pact. Las expectativas de los consumidores sobre una API se codifican como pruebas que el servicio proveedor debe cumplir antes de desplegarse. Si el servicio de pagos quiere cambiar el formato de su respuesta, las pruebas de contrato fallan antes de que ese cambio llegue a producción y rompa a sus consumidores. La verificación es rápida, independiente y no requiere levantar múltiples servicios al mismo tiempo.
La estrategia de testing recomendada combina: pruebas unitarias de lógica interna, pruebas de contrato entre servicios, y monitoreo semántico en producción para verificar que el sistema funciona desde la perspectiva del usuario real.
Escalabilidad de bases de datos
Cuando las bases de datos alcanzan sus límites de rendimiento, las opciones son:
- Réplicas de lectura: copias de la base de datos que solo aceptan lecturas. Las escrituras van al nodo primario y se replican asíncronamente. Ideal cuando el sistema tiene muchas más lecturas que escrituras.
- Sharding (particionamiento horizontal): dividir los datos en múltiples bases de datos según algún criterio (por región, por rango de ID). Escala las escrituras pero agrega complejidad operativa significativa.
- CQRS: separar el modelo de lectura del de escritura permite optimizar cada uno independientemente.
En ningún caso la solución es compartir la base de datos entre servicios. Eso siempre es peor que cualquier complejidad que introduzcan las alternativas.
Observabilidad: lo que hace posible operar el sistema
Un monolito falla en un lugar. Un sistema de 20 microservicios puede fallar en cualquiera de sus 400 puntos de integración posibles. Sin observabilidad, estás volando a ciegas.
El stack mínimo que Newman considera no negociable:
- Logs estructurados centralizados: todos los servicios loguean en JSON a un colector central. La búsqueda por
correlation_idpermite ver el recorrido completo de una request a través de todos los servicios que participaron. - Correlation IDs: un identificador único generado en la primera llamada, propagado en todos los headers hacia cada servicio que participa en esa transacción. Sin esto, correlacionar un error en el servicio F con la request original que llegó al servicio A es prácticamente imposible.
- Monitoreo semántico: no alcanza con saber que los servidores están vivos. Necesitás transacciones sintéticas que se ejecuten periódicamente en producción para verificar que el sistema funciona desde la perspectiva del usuario real.
- Health checks: cada servicio expone un endpoint
/healthque el orquestador (Kubernetes, ECS) usa para decidir si debe reiniciarlo o dejar de enviarle tráfico.
Caché: rendimiento y resiliencia
El almacenamiento en caché no solo mejora el rendimiento, sino que provee resiliencia: si un servicio falla, se puede servir información en caché. Newman identifica tres ubicaciones clave para implementarlo:
- Del lado del cliente: el consumidor guarda la respuesta y la reutiliza sin llamar al servicio. Reduce latencia al mínimo posible.
- Del lado del servidor: el servicio guarda respuestas costosas de computar, evitando recalcularlas.
- En un proxy intermediario: un componente entre el cliente y el servidor (como Varnish o un API Gateway con caché) intercepta las respuestas y las sirve directamente sin llegar al servicio.
La advertencia crítica es la invalidación de caché: si los datos cambian y la caché no se invalida correctamente, los clientes reciben información desactualizada. El “envenenamiento de caché” —donde datos incorrectos quedan persistidos— es uno de los bugs más difíciles de diagnosticar en producción.
Seguridad en sistemas distribuidos
El modelo de seguridad de un monolito es simple: la aplicación está autenticada o no. En microservicios, cada llamada entre servicios es una potencial superficie de ataque.
El problema del Confused Deputy describe el escenario donde un servicio malicioso engaña a un servicio intermedio para que acceda a datos de un tercero en su nombre. La solución es “confianza cero” entre servicios: cada llamada service-to-service debe estar autenticada con tokens HMAC o certificados TLS mutuos, incluso dentro de la red interna.
Para usuarios externos, el patrón correcto es un API Gateway con Single Sign-On (SSO/OAuth2/OpenID Connect) que emite tokens delegados que los servicios internos pueden validar. Newman propone un enfoque de “defensa en profundidad”: múltiples capas de validación, no solo en el perímetro.
El Teorema CAP: la decisión que no podés evitar
El Teorema CAP dicta que, en presencia de una partición de red —que es inevitable en sistemas distribuidos—, un sistema debe elegir entre ofrecer Consistencia (C) o Disponibilidad (A).
Consistencia significa que todos los nodos ven los mismos datos al mismo tiempo. Disponibilidad significa que el sistema responde a todas las requests, aunque algunos nodos estén caídos.
Los arquitectos deben decidir explícitamente, para cada microservicio, cuál es la prioridad: ¿el servicio debe rechazar solicitudes (sacrificando disponibilidad) para mantener los datos estrictamente consistentes? ¿O debe responder con datos potencialmente desactualizados (sacrificando consistencia) para mantenerse siempre disponible?
No hay una respuesta universal. El servicio de saldos de cuentas bancarias prefiere consistencia. El servicio de recomendaciones de productos puede tolerar datos con segundos de retraso.
La Ley de Conway: tu arquitectura refleja tu organización
Newman dedica atención especial a una observación que tiene décadas pero sigue siendo ignorada: la arquitectura de software tiende a reflejar las estructuras de comunicación de la organización que la construye.
Si tenés un equipo de frontend, un equipo de backend y un equipo de base de datos trabajando en silos, vas a producir una arquitectura de tres capas. Si querés microservicios autónomos, necesitás Feature Teams autónomos: equipos que poseen un servicio de punta a punta, incluyendo su base de datos, su API y su interfaz.
Los límites de los servicios deben alinearse con los límites de los equipos. Si no, la arquitectura técnica y la organizacional van a estar en conflicto permanente, y siempre gana la organización.
Documentación viva: contratos que se ejecutan
En un ecosistema con decenas de servicios, la documentación estática muere rápido. Un README que describe una API que cambió hace tres semanas es peor que no tener documentación: genera confianza falsa.
Newman recomienda herramientas como Swagger (hoy OpenAPI) y navegadores HAL (Hypertext Application Language), que actúan como contratos visuales donde un desarrollador no solo lee los parámetros de una API, sino que puede ejecutar peticiones de prueba directamente desde la misma documentación. La documentación y el contrato son la misma cosa, y se actualizan juntos.
Combinado con Consumer-Driven Contracts, esto crea un ecosistema donde los cambios de API son detectables antes de que lleguen a producción y donde la documentación refleja siempre el estado real del sistema.
Cuándo NO usar microservicios
Esto es lo que pocos artículos dicen, pero Newman dedica páginas enteras a explicarlo.
No uses microservicios si:
- Tu dominio no está claro. Proyectos greenfield o áreas de negocio que todavía están definiendo qué hacen no tienen las fronteras estables que requiere una buena descomposición. Empezá con un monolito bien modularizado. Las fronteras internas (módulos) pueden convertirse en servicios cuando el dominio lo justifique.
- Tu equipo es pequeño. La complejidad operativa de microservicios requiere madurez en CI/CD, observabilidad, service discovery e infraestructura. Un equipo de tres personas tiene otras prioridades.
- El sistema no necesita escalar en partes independientes. Si todo el sistema crece o decrece uniformemente, el overhead de los microservicios no se justifica.
- No tenés cultura de automatización. Sin CI/CD maduro, los microservicios se convierten en una pesadilla operativa. El despliegue manual de 20 servicios es inmanejable.
La referencia completa: blueprint visual
El PDF a continuación resume los patrones, flujos y decisiones arquitectónicas presentados en esta guía. Es una referencia de trabajo, pensada para consultar mientras diseñás o revisás una arquitectura.
Casos de uso: qué tipo de microservicio necesitás
No todos los microservicios son iguales. Según la responsabilidad que tengan en el sistema, se diseñan con patrones y bases de datos completamente distintos.
Microservicio de entidad (core domain)
Responsabilidad: administrar todo el ciclo de vida y las reglas de negocio de un concepto central del dominio.
Caso de uso: el sistema de gestión de pedidos (OrderService). Es el único dueño de la base de datos de pedidos. No expone operaciones CRUD, sino intenciones de negocio: AprobarPedido(), CancelarPedido(). Cualquier otra área del sistema pasa por este servicio para consultar o modificar el estado de un pedido.
Backend for Frontend (BFF)
Responsabilidad: actuar como orquestador y adaptador de formato para interfaces de usuario específicas.
Caso de uso: una plataforma de e-commerce con app móvil iOS, web de escritorio y API pública. En lugar de una sola API gigantesca para los tres clientes, se construye un “Mobile BFF”, un “Web BFF” y un “API BFF”. El Mobile BFF llama a los servicios internos, reduce los payloads pesados y devuelve JSON comprimido para no agotar datos móviles ni batería.
Capa anticorrupción
Responsabilidad: aislar los sistemas internos modernos de sistemas legados cerrados o proveedores de terceros.
Caso de uso: integración con un ERP mainframe corporativo o una pasarela de pago externa (Stripe, PayPal). El microservicio adaptador recibe órdenes desde el ecosistema interno con un modelado de negocio limpio y las traduce a las engorrosas llamadas SOAP o protocolos propietarios del sistema heredado. Si el ERP se reemplaza mañana, solo se modifica este servicio, protegiendo al resto del sistema.
Worker asincrónico
Responsabilidad: absorber picos de tráfico y realizar tareas pesadas en segundo plano de manera desacoplada.
Caso de uso: transcodificación de video, generación masiva de facturas PDF a fin de mes, envío de emails en lote. Estos servicios típicamente no tienen interfaces HTTP. Escuchan una cola de mensajería (RabbitMQ, Kafka), toman un evento, procesan de forma intensiva y publican un nuevo evento indicando que terminaron.
Microservicio de lectura materializada (CQRS data pump)
Responsabilidad: proveer consultas extremadamente rápidas para reportes y paneles analíticos consolidados.
Caso de uso: un panel de Business Intelligence que necesita métricas cruzadas entre clientes, inventarios y ventas en tiempo real. El microservicio de reportes escucha pasivamente cada evento del sistema y actualiza continuamente una base de datos propia orientada a lectura (Elasticsearch, MongoDB), devolviendo información analítica de forma instantánea sin tocar los servicios transaccionales.
Resumen de decisiones arquitectónicas
| Decisión | Opción A | Opción B | Recomendación de Newman |
|---|---|---|---|
| Coordinación de flujos | Orquestación | Coreografía | Coreografía |
| Comunicación | Síncrona (REST) | Asíncrona (eventos) | Asíncrona cuando sea posible |
| Service discovery | DNS | Registro dinámico (Consul) | Registro dinámico en sistemas grandes |
| Testing de integración | E2E | Consumer-Driven Contracts | CDCs |
| Despliegue | Múltiples servicios por pipeline | Un servicio por pipeline | Un servicio por pipeline |
| Infraestructura | Servidor compartido | Contenedor por servicio | Contenedor por servicio |
| Código compartido | Librerías centralizadas | Service templates | Service templates |
Siguiente paso
Si estás evaluando si tu sistema actual necesita una reestructuración arquitectónica, o si estás diseñando uno nuevo y querés evitar los errores más comunes, puedo hacer un análisis funcional de lo que tenés y ayudarte a definir la estrategia correcta.
No siempre la respuesta es microservicios. A veces es un monolito bien modularizado. A veces es extraer un servicio específico. La diferencia entre las tres opciones puede ser de meses de trabajo y cientos de miles de pesos en costos de migración.
Escribinos por WhatsApp o por email y arrancamos con un diagnóstico sin costo.
Fuentes y referencias
- Building Microservices, 2nd Edition — Sam Newman (2021)